
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 리버싱
- rev
- CodeEngn
- 프로그래머스
- x64
- stack frame
- RVA
- x32
- 크랙미
- __stdcall
- Programmers
- Python
- 실행파일
- Rich Header
- image section header
- __cdecl
- Image dos header
- 리치헤더
- Reversing
- __vectorcall
- 코드엔진
- __fastcall
- Dos Stub
- pe format
- 32bit
- 파이썬
- Calling Convention
- crackme
- ABI
- 함수 호출 규약
- Today
- Total
kj0on
[Definition] x64 ABI 본문
1. 정의
ABI (Application Binary Interface)는 어플리케이션과 운영체제 또는 컴파일된 코드 간의 상호작용 방식을 정의한 이진 수준의 규약이다. 쉽게 말해, 컴파일된 바이너리들이 서로 호환되도록 하는 규칙 모음을 뜻한다.
2. x64 ABI
| 규칙 | 역할 | 필수 규칙(ABI) | 조건부 규칙 |
| 스택 정렬 규칙 | Alignment (정렬) |
프롤로그, 에필로그을 제외한 모든 구간에서 RSP ≡ 0 (mod 16)을 유지해야 한다. | Leaf 함수는 정렬을 다시 맞출 필요가 없다. 이후의 단계에서 정렬이 보장되어 있는 경우는 제한적으로 정렬을 유지하지 않아도 된다. |
| 섀도우 스페이스 규칙 | Call Setup (호출 준비) |
Caller(호출자)는 언제나 32byte Shadow Space를 확보한 상태에서 함수를 호출해야 한다. Callee(피호출자)는 해당영역을 자유롭게 덮어써도 무방하다. | - |
| 레지스터 보존 규칙 | Register Save (레지스터 보존) |
Callee(피호출자)에서 비휘발성 레지스터를 사용했다면 함수 내부에서 원래 값으로 복구해야 한다. | 비휘발성 레지스터를 사용하지 않았다면 저장, 복구 코드가 없어도 된다. |
| 언와인드 데이터 규칙 | Unwind Info (예외 복구) |
스택, 콜, 예외, 로컬변수를 사용하는 모든 프레임 함수는 RUNTIME_FUNCTION + UNWIND_INFO을 기록해야 한다. | Leaf 함수는 생략 가능하다. |
| 함수 호출 규약 | Parameter Passing (인자 전달) |
첫 4개의 정수형 인자는 RCX, RDX, R8, R9에, 부동소수점 인자는 XMM0–3에 전달한다. | 5번째 이후의 인자는 스택에 저장된다. |
3. 스택 정렬 규칙
정렬
대부분의 구조체는 자연 정렬에 맞춰 정렬됩니다. 기본 예외는 스택 포인터와 malloc 또는 alloca 메모리로, 성능을 지원하기 위해 16바이트로 맞춥니다. 16바이트 이상의 맞춤은 수동으로 수행해야 합니다. 16바이트는 XMM 작업의 일반적인 맞춤 크기이므로 대부분의 코드에서 이 값이 유효합니다. 구조체 레이아웃 및 맞춤에 대한 자세한 내용은 x64 형식 및 스토리지 레이아웃을 참조 하세요. 스택 레이아웃에 대한 자세한 내용은 x64 스택 사용을 참조하세요.
스택은 항상 16바이트 맞춤 상태로 유지되지만, 반환 주소가 푸시된 후와 같이 프롤로그 내부에서 지정된 경우와
함수 형식에 특정 프레임 함수 클래스용으로 표시된 경우는 예외입니다.
스택 정렬은 스택 포인터가 가리키는 주소(RSP)가 특정 배수로 맞춰져 있어야 한다는 규칙이다. Windows x64 ABI에서는 함수 프롤로그, 에필로그를 벗어난 모든 지점에서 RSP ≡ 0 (mod 16)이 의무사항이고, 리프(Leaf) 함수만 예외적으로 이 요구를 다시 충족하지 않아도 된다.

스택 정렬 규칙에 따르면 XMM 작업의 일반적인 맞춤 크기 때문에 128bit(16byte)에 해당하는 정렬을 사용한다고 명시되어 있다. 그런데 32bit 환경의 __vectorcall 역시 XMM 레지스터를 사용하지만, x86 ABI가 보장하는 스택 정렬은 최소 4byte에 불과하다. 반면 64bit ABI는 함수 바디 구간에서 RSP ≡ 0 (mod 16)을 강제해 16byte 정렬을 반드시 지키게 한다. 64비트도 32비트와 마찬가지로 한 번에 처리할 수 있는 크기를 생각해 본다면 64bit(8byte) 정렬을 따르는 것이 꽤나 일반적으로 보인다. 그런데 왜 64bit(8byte) 정렬이 아닌 128bit(16byte) 정렬을 따라야 하는 것일까? 이는 단순한 연산 단위 때문이 아니라, SIMD 명령어의 정렬 요구사항과 향후 AVX 확장까지 고려한 플랫폼 수준의 정렬 정책 때문이다.
| 명령어 | 약어 의미 | 전송 | 정렬 제약 | 사용 이유 |
| MOVAPS/ MOVAPD |
Aligned Packed Single/ Aligned Packed Double |
128bit(16byte) | 128bit(16byte) 정렬 필수, 어기면 #GP 발생 | 정렬된 SIMD 데이터 고속 처리 |
| MOVUPS/ MOVUPD |
Unaligned Packed Single/ Unaligned Packed Double |
128bit(16byte) | 정렬 불필요 (임의 주소 허용) | 정렬 보장 없는 메모리 접근 시 사용 |
| MOVSS/ MOVSD |
Scalar Single/ Scalar Double |
32bit(4byte)/ 64bit(8byte) |
32bit(4byte) 정렬 권장/ 64bit(8byte) 정렬 권장 |
단일 float 값 로드, 저장/ 단일 double 값 로드, 저장 |

역사적으로 MOVUP 명령어는 정렬된 주소에서도 상대적으로 느린 동작을 보였으며, 이는 같은 128bit(16byte) 크기의 데이터를 처리하는 MOVAP 명령어가 메모리와 XMM 레지스터 간의 데이터 전송을 한 번에 수행할 수 있었기 때문이다. MOVAP는 메모리 주소가 128bit(16byte) 경계에 정렬되어 있는 경우에만 빠르게 동작하며, 그렇지 않으면 #GP(General Protection) 예외를 발생시킨다. 이에 반해 MOVUP는 정렬을 보장할 수 없는 상황에서 안정성을 확보하기 위해 사용되었으나, 초기 x86 SSE 지원 CPU에서는 내부적으로 정렬 여부를 매번 확인해야 했고, 이로 인해 명령어 자체가 느릴 수밖에 없었다. 따라서 성능 측면에서 보면 조건 분기를 넣어 정렬 여부를 검사하느니, 애초에 데이터 구조를 16byte 단위로 정렬하여 MOVAPS 같은 정렬 기반 명령어를 사용하는 것이 더 효율적이고 단순한 방식으로 여겨졌다. 따라서 CPU가 예외 없이 빠르게 SIMD 명령어를 처리하도록 ABI 차원에서 성능을 이유로 16byte 정렬 규칙이 도입되었다.

Haswell 이후 부터 최근 CPU 마이크로아키텍처에서는 MOVAP와 MOVUPS 성능 차이가 거의 사라졌다. 하지만 여전히 일부 SIMD 명령어는 비정렬 접근 시 #GP 예외를 일으킨다. 결국, 현대 하드웨어에서 성능상의 정렬 요구 조건이 완화되었음에도 불구하고 16byte 정렬 규칙을 폐지할 수 없는 것은, 이와 같은 예외 상황을 방지하여 시스템의 안정성을 유지하고, 기존 소프트웨어와의 ABI 차원에서의 호환성을 지속적으로 보장하기 위한 것이다.
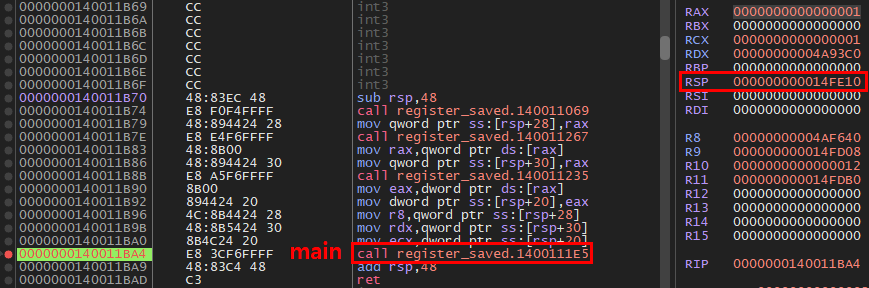
실제로 x64 ABI의 스택 정렬 규칙을 확인해 보면, 프로그램의 진입점인 main 함수 호출 직전에 이미 RSP 레지스터는 16바이트(0x10) 정렬 상태임을 관찰할 수 있다. 이는 함수 body에서 RSP ≡ 0 (mod 16)을 보장하는 플랫폼의 기본 규칙 때문으로, Caller(호출자)가 미리 정렬 상태를 준비해 두고 Callee(피호출자)는 이를 신뢰하고 바로 SIMD 연산 등을 수행할 수 있도록 설계된 것이다.

최적화 수준 /O2를 적용한 main 함수에서는 Opt-Mid 패턴이 나타나는 것을 확인할 수 있다. 이때 sub rsp, 0x28 명령어가 등장하는데, 이는 main 함수 진입 전에 호출자가 call main을 수행하면서 실행된 push rip에 의해 RSP가 8byte 증가한 것을 보정하기 위한 것이다. 따라서 body 구간에서 다시 16byte 정렬를 맞추기 위해 이를 포함한 추가적인 0x8 보정이 필요해지며, 결과적으로 0x20에 8byte를 더한 0x28 만큼 RSP를 감소시키는 명령이 수행되는 것이다. 이 보정으로 인해 main함수의 body에서는 16byte 정렬이 일관되게 유지된다.

push 및 pop 명령어는 스택 포인터를 변경하므로, 스택 정렬 규칙을 위반할 수 있다. 따라서 x64 에서는 이러한 명령의 사용을 각각 함수의 프롤로그와 에필로그 구간으로 제한하고 있다. 이로 인해 함수 프롤로그가 끝나고 본격적인 body 구간이 시작되면 에필로그가 나타나기 전까지 스택 포인터는 고정된 값을 유지한다. 실제로 컴파일된 x64 코드를 분석해 보면 함수의 body에서 push나 pop 명령어가 나타나지 않는것을 확인할 수 있으며, 이는 정렬을 일관되게 유지하기 위한 설계적 특징으로 볼 수 있다. 결과적으로 프롤로그와 에필로그 사이에서 RSP는 전혀 변경되지 않는 것이 x64 함수의 중요한 특징 중 하나이다. 다만, 함수를 호출할 때와 같이 프롤로그 단계에서 정렬이 보장되어 있는 경우는 body 내부에서도 제한적으로 push를 사용할 수 있다.
4. 섀도우 스페이스 규칙
| 용어 | 출처 |
| Shadow Space | MSDN, LLVM, Intel, Wikipedia, Community |
| Shadow Store | MSDN, System V AMD64 ABI, StackOverflow, Reddit |
| Shadow Area | LLVM |
| Argument Homing Space | AMD |
| Prameter Homing Space | CodeMachine |
| Homing Space | CodeMachine |
| Home Space | Github, StackOverflow |
| Spill Space | StackOverflow |
| Spill Slot | Blog |
x64 Architecture에서 Caller(호출자)가 함수 호출 시 스택에 미리 할당하는 레지스터 저장 영역에 관하여 여러 문서와 커뮤니티에서 서로 다른 명칭을 사용하고 있어 이를 정리할 필요가 있다. MSDN, LLVM, Intel의 공식 문서와 Wikipedia 등 여러 문헌에서는 이 영역을 "Shadow Space"라는 용어로 기술하고 있으나, 일부 공식 문서나 비공식적인 커뮤니티 및 블로그에서는 다른 용어들이 사용되기도 한다. 따라서 나타난 사용 빈도와 공식 문서의 채택 여부를 고려했을 때, "Shadow Space"가 해당 영역을 지칭하는 가장 공식적인 용어라고 판단할 수 있다.
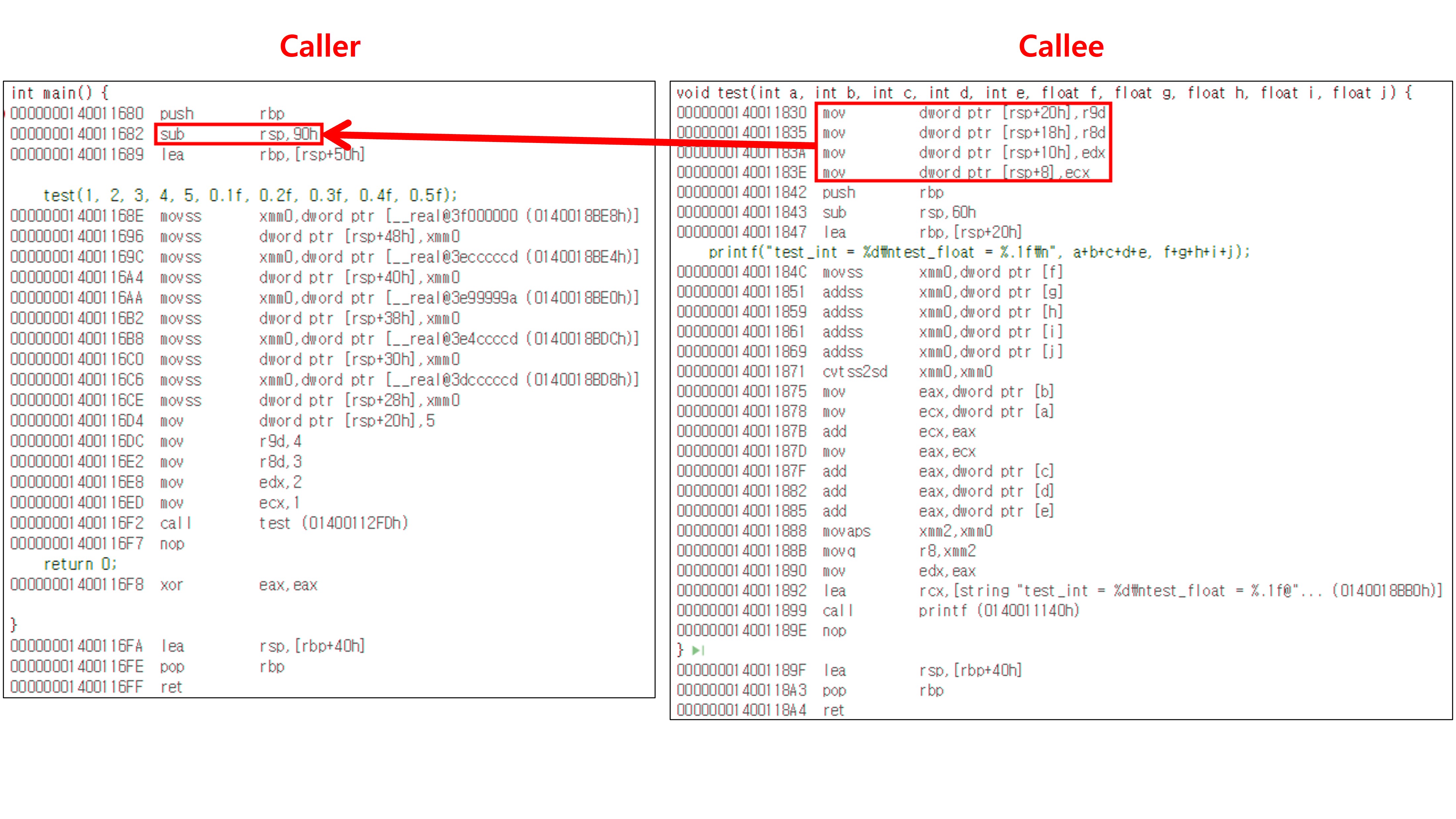
Shadow Space는 Caller(호출자)가 함수를 호출하기 전에 RCX, RDX, R8, R9(또는 XMM0~XMM3) 레지스터를 저장해둘 수 있도록 예약하는 스택 상의 32byte 공간을 의미한다. 이 공간은 함수 인자 4개에 대응하는 레지스터 값을 Callee(피호출자) 함수 내부에서 백업하거나 참조할 수 있도록 보장하는 역할을 한다. 이 영역은 레지스터 인자가 4개가 아닌 경우(0~3)에도 반드시 32Byte 전체의 공간이 필요하다. 따라서 함수 호출 시, 호출자는 Shadow Space 영역을 고려해 스택의 영역을 0x20(32byte) 이상만큼 확보해야 한다. 이때, 스택 정렬 규칙에 따라 16byte 정렬을 유지해야 한다. (그 밑의 lea rbp, [rsp+50h]는 로컬 변수영역의 경계 역할을 하는 코드다.)

함수 호출 규약에 따라 RCX, RDX, R8, R9순으로 인자를 넣고 있다. 5번째 부터는 인자값을 스택으로 전달하고 있는데, 그 위치를 자세히 보면 [rsp+0x0]이 아닌 [rsp+0x20]으로, Shadow Space 영역을 피해서 값을 저장하는 것을 확인할 수 있다. 이는 Callee(피호출자)에서 Shadow Space 영역의 사용을 보장하기 위함이다.
The called function effectively owns this space and can use it for any purpose, so the calling function cannot rely on its contents on return. Register parameters occupy the least significant ends of registers and shadow space must be allocated for four register parameters even if the called function doesn’t have this many parameters.
이 공간은 호출 시점에서 Caller(호출자)가 확보하지만, 해당 영역은 Callee(피호출자)가 완전히 소유하는 것으로 간주되며, Callee(피호출자)는 이를 자유롭게 덮어쓰거나 임시 용도로 사용할 수 있다. 따라서 Caller(호출자)는 이 공간의 내용을 복귀 시점에서 신뢰하거나 재사용할 수 없기 때문에 함수 호출 전, 이 공간에 값을 저장하는 것은 무의미하다. 또한 Callee(피호출자)의 매개변수가 많지 않더라도(4미만), Caller(호출자)는 항상 이 32바이트의 Shadow Space를 확보해야 한다.

Callee(피호출자)는 함수 내부에서 Shadow Space가 존재한다는 사실을 암묵적으로 신뢰하고, 별도 확인 작업 없이 자유롭게 덮어쓸 수 있어야 한다. 다만, 해당 공간을 홈 슬롯(Home Slot) 용도로만 사용하는 것이 아니라, 임시 변수 저장이나 기타 목적에도 활용할 수 있다. 주로 이 공간은 첫 네 개의 레지스터 인자 값을 메모리로 저장할 필요가 있을 때 사용되지만, 반드시 사용해야 하는 것은 아니며, 함수 최적화 수준이나 구현 방식에 따라 생략되기도 한다. 또한 이 공간이 인자 값을 저장하는 것 외에도 목적에 따라 다양한 방식으로 활용될 수 있다.
| 구분 | 설명 |
| 가변 인자 함수 | 매크로가 레지스터가 아니라 메모리 배열을 순회하기 때문에 레지스터 파라미터를 스택으로 옮겨 한 덩어리로 다룰 수 있게 한다. |
| 디버그(/Od) 빌드 | 디버거, 크래시덤프에서 파라미터 값을 메모리에서 복구할 때 사용할 수 있으며 디버깅을 좀 더 용이하게 하기 위해 사용하기도 한다. |
| 파라미터의 주소가 필요할 때 | 레지스터 값은 주소가 없으므로 해당 파라미터를 스택에 저장해 주소를 참조할 수 있게 한다. |
| 함수를 호출하기 전에 해당 인자 값을 보존해야 할 때 | 함수 호출 뒤에도 값이 필요하면 임시 보관 장소로 사용한다. |
| 언와인딩 메타데이터가 레지스터 값을 스택에 있었다고 가정 할 때 | 일부 컴파일러에서 예외 처리 복구용으로 필요하다. |
Shadow Space는 단순히 인자의 백업 공간에 그치지 않고, 함수의 특성이나 빌드 설정, 디버깅 지원, 예외 처리 등 다양한 상황에 따라 유연하게 활용되는 구조적 여유 공간이다. 정해진 용도만을 위한 고정된 공간이 아니라, 함수 내부의 요구에 따라 다목적으로 활용 가능한 공간으로 기능한다.
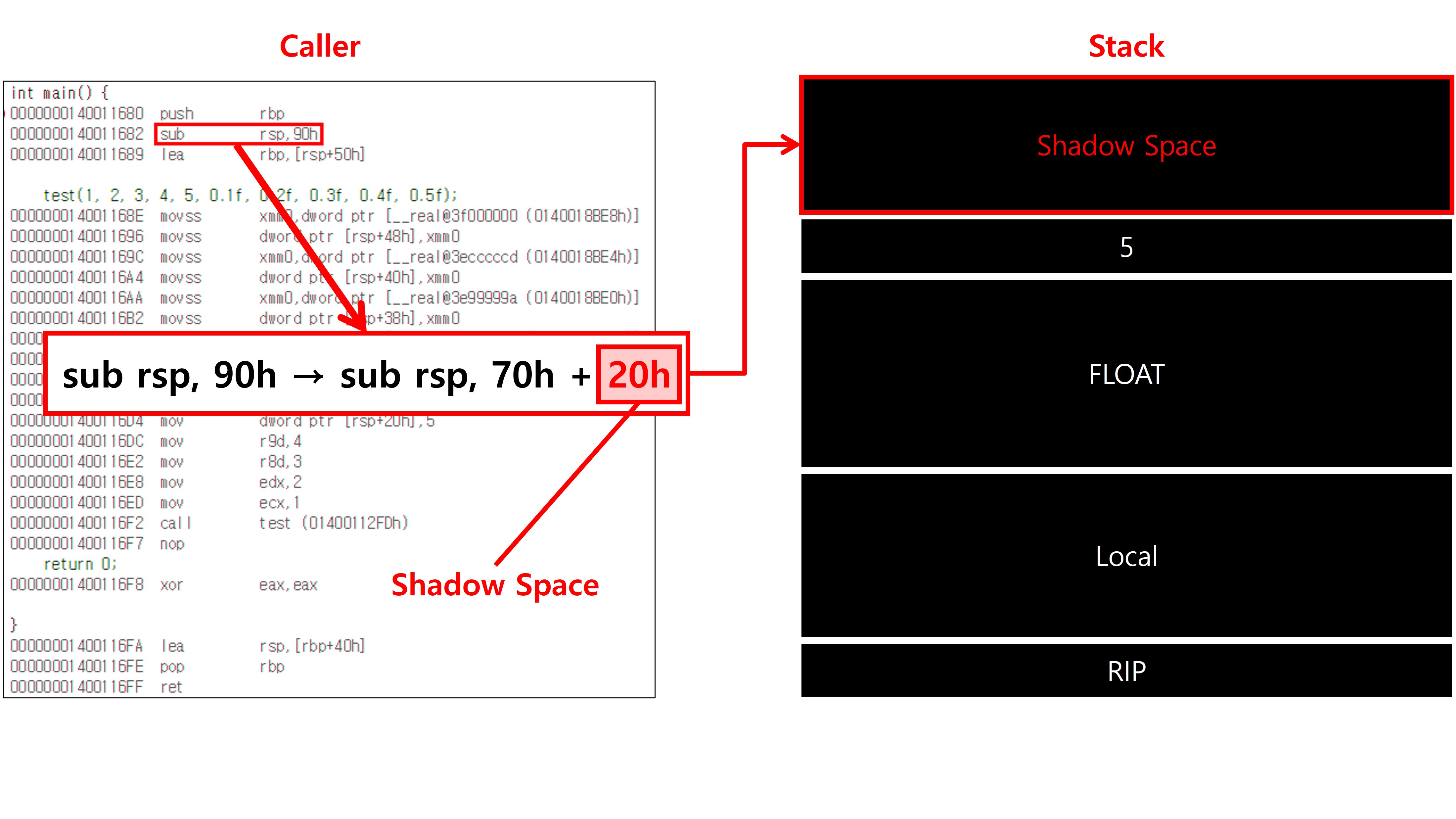
Windows x64 ABI에서 Shadow Space는 사용 여부와 무관하게 Caller(호출자)가 반드시 32바이트를 확보해야 하는 구조적 요구사항이며, 이는 함수의 인자 개수나 함수 내부 구현과는 전혀 관련이 없다. 다시 말해, 이 공간이 실제로 쓰이든 쓰이지 않든 관계없이 함수를 호출하기 전에는 반드시 32byte를 확보해야 하는 것이 ABI 차원에서의 규칙이다. 이 규칙을 어기는 경우는 매우 제한적인 상황에 국한된다. 따라서 Shadow Space 관련 명령이 명시적으로 보이지 않더라도, 규칙상 항상 확보되어 있다고 보는 것이 원칙이며, 이는 함수가 이를 실제로 사용할지를 떠나 호출 시점에서 반드시 지켜져야 하는 전제 조건이다.
5. 레지스터 보존 규칙
x64 호출 규칙
x64 ABI는 레지스터 RAX, RCX, RDX, R8, R9, R10, R11 및 XMM0-XMM5를 휘발성으로 간주합니다. 있는 경우 YMM0-YMM15 및 ZMM0-ZMM15의 상위 부분도 휘발성입니다. AVX512VL에서 ZMM, YMM 및 XMM 레지스터 16-31도 휘발성입니다. AMX 지원이 있는 경우 TMM 타일 레지스터는 휘발성입니다. 전체 프로그램 최적화와 같은 분석으로 안전성을 입증할 수 없는 경우 휘발성 레지스터는 함수 호출 시 소멸된 것으로 간주합니다.
x64 ABI는 레지스터 RBX, RBP, RDI, RSI, RSP, R12, R13, R14, R15 및 XMM6-XMM15를 비휘발성으로 간주합니다. 이들 레지스터는 그것들을 사용하는 함수에 의해 저장되고 복원되어야 합니다.
x64 ABI 규칙 개요
x64 아키텍처는 범용 레지스터 16개(이하 '정수 레지스터')와 부동 소수점용으로 사용 가능한 XMM/YMM 레지스터 16개를 제공합니다. 휘발성 레지스터는 호출자가 호출 중에 내용이 손실될 수 있는 것으로 가정하는 임시 저장소입니다. 함수 호출 중에 값을 유지하려면 비휘발성 레지스터가 필요합니다. 호출 수신자는 비휘발성 레지스터(사용하는 경우)를 저장해야 합니다.
Windows x64 호출 규약을 정의하는 Microsoft의 문서에 따르면, x64 ABI는 레지스터를 휘발성(volatile)과 비휘발성(non-volatile)으로 구분하며, 이 구분은 함수 호출 시 레지스터의 값 보존 책임을 명확히 하기 위한 목적에서 도입되었다. 문서에 따르면, 휘발성 레지스터는 호출자가 호출 중에 손실될 수 있을 것으로 가정하고 있다. 즉, 휘발성 레지스터는 필요시 Caller(호출자)에 의해 저장 및 복원 해야한다. 함수 호출 중에 값을 유지하려면 비휘발성 레지스터가 필요하다고 하는데, 이 말은 비휘발 레지스터는 호출자가 호출 중 값을 유지할 수 있다는 것을 의미한다. 즉, 비휘발성 레지스터는 Callee(피호출자)에 의해 저장 및 복원되는 레지스터이며, 공식문서에서도 호출 수신자는(Callee) 비휘발성 레지스터(사용하는 경우)를 저장해야 한다고 명시하고 있다.

| 분류 | 보존 책임 | 의미 |
| 휘발성 레지스터 (Volatile) | Caller-Saved | 호출 직후 값이 보존된다고 기대할 수 없다. 필요하면 호출자가 따로 저장해야 한다. |
| 비휘발성 레지스터 (non-Volatile) | Callee-Saved | 호출 전, 후의 값이 같아야 한다. 피호출자가 해당 레지스터를 쓰면 반드시 원래 값으로 복구해야 한다. |
휘발성(volatile), 비휘발성(non-volatile)는 레지스터 자체의 물리적인(하드웨어) 특성이 아닌, Caller(호출자)의 시점에서 바라본 레지스터의 특성이다. Caller(호출자) 입장에서는 휘발성 레지스터는 Callee(피호출자)가 보존해 주지 않기 때문에 호출 시점에서 값이 변경(휘발성) 될 수 있다고 보는것이다. 반대로 비휘발성 레지스터는 Callee(피호출자)가 함수 내부에서 직접 보존하기 때문에 호출 시점에 값이 변경되지 않는(비휘발성)것으로 판단할 수 있다는 것이다.
| 구분 | 레지스터 |
| 휘발성 레지스터 |
RAX, RCX, RDX, R8, R9, R10, R11, XMM0-XMM5, YMM0-YMM5, ZMM0-ZMM5 |
| 비휘발성 레지스터 |
RBX, RBP, RDI, RSI, RSP, R12, R13, R14, R15, XMM6-XMM15, YMM6-YMM15, ZMM6-ZMM15 |
MS 공식 문서에서는 위와 같이 레지스터를 휘발성과 비휘발성으로 구분한다. 자주 덮어쓰는 값은 휘발성, 오래 보존할 값은 비휘발성으로 지정되며, 용량이 큰 레지스터는 저장 부담 때문에 일부만 비휘발성이다.
| 설계 목표 | 설명 |
| 호출자, 피호출자 간 비용 부담 분배 | 모든 레지스터를 항상 callee-saved(피호출자 보존)로 지정하면 모든 함수의 prologue와 epilogue에 push와 pop이 반복되어 코드 크기와 스택 사용량이 증가하는 문제가 생긴다. 반면, 모든 레지스터가 caller-saved(호출자 보존)로 지정되면 호출이 발생할 때마다 호출자가 직접 레지스터 값을 보존해야 해서 호출 빈도가 높을수록 오버헤드가 커진다. 따라서 ABI는 호출자와 피호출자가 모두 보존하도록 비용을 나눠 균형있게 분담하도록 한다. |
| 데이터 수명에 따른 역할 분담 | 데이터의 생명주기(lifetime)를 기준으로, 루프 인덱스나 베이스 포인터와 같은 장기간 살아 있는 값은 비휘발성 레지스터에, 반대로 임시적이고 짧은 계산에 사용되는 값은 휘발성 레지스터에 할당 하고 있다. 호출자는 장기 데이터를 안전하게 유지하면서도, 단기적인 계산에서는 부담 없이 레지스터를 자유롭게 사용할 수 있다. |
| 컴파일러 최적화 | 컴파일러가 레지스터 할당할 때 함수 내 호출 빈도에 따라 휘발성 레지스터, 비휘발성 레지스터의 비용(weight)을 다르게 설정하는 휴리스틱을 적용해 최적화를 수행한다. 이 구분을 활용하여 불필요한 메모리 접근 횟수를 감소시킬 수 있다. |
| 다양한 언어 및 모듈 간 호환성 | 저장 및 복원의 책임이 모듈마다 다르다면 링크는 가능할지 몰라도 실행 과정에서 상태가 훼손되어 제대로 동작하지 않을 위험이 있다. |
비휘발성 및 휘발성 레지스터 구분은 호출자와 피호출자간의 효율적인 역할 분담과 비용 최소화를 위해 필수적이다. 모든 레지스터를 동일하게 취급하여 보존 여부를 상황에 따라 결정하면 각 함수를 호출될 때마다 추가적인 분석과 판단이 요구되어 컴파일러 및 런타임 오버헤드가 발생할 수 있다. 또한, 이 경우 호출자와 피호출자 간의 보존 규약이 명확하지 않아 서로 다른 모듈이나 언어 간 상호작용 시 예기치 않은 상태 변경으로 인한 오류 위험이 증가한다. 반면, ABI에서 레지스터를 미리 휘발성과 비휘발성으로 명확히 구분하면 호출 시점마다 보존 여부를 판단할 필요가 없어지고, 각 함수는 이 규약을 신뢰하여 독립적으로 최적화된 코드를 생성할 수 있다. 결과적으로 이러한 명확한 구분은 코드의 안정성 및 유지보수성을 높이고, 다양한 언어나 모듈 간의 원활한 연동과 함께 컴파일러의 최적화 효율을 극대화하는 데 기여한다.
6. 언와인드 데이터 규칙
언와인드 데이터(Unwind Data)란, Windows x64 환경에서 예외(Exception) 발생 시나 스택 추적(Stack Unwinding) 시에 스택 프레임을 정확히 복원할 수 있도록 돕는 추가적인 메타데이터(metadata)를 의미한다. 이는 함수가 실행될 때 어떻게 스택을 변경했는지를 기록한다. RUNTIME_FUNCTION, UNWIND_INFO, UNWIND_CODE 라는 구조체로 나타나며, x64 ABI 규약 중 하나다.
typedef struct _RUNTIME_FUNCTION {
DWORD BeginAddress; // Function start address
DWORD EndAddress; // Function end address
union {
DWORD UnwindInfoAddress; // Unwind info address
DWORD UnwindData; // Alternative name for the same field
} DUMMYUNIONNAME;
} RUNTIME_FUNCTION, *PRUNTIME_FUNCTION;_RUNTIME_FUNCTION 구조체는 PE 포맷의 예외 처리 테이블에서 각 함수에 대한 정보를 저장하기 위해 사용되며, 함수의 시작 주소와 끝 주소, 그리고 해당 함수에 연관된 언와인드 정보의 RVA를 포함한다. 언와인드 정보는 UnwindInfoAddress 또는 UnwindData로 명명된 필드를 통해 참조되며, 두 이름은 동일한 필드를 가리키는 대체 표현이다.
typedef struct _UNWIND_INFO {
BYTE Version : 3; // Version
BYTE Flags : 5; // Flags
BYTE SizeOfProlog; // Size of prolog
BYTE CountOfCodes; // Count of unwind codes
BYTE FrameRegister : 4; // Frame Register
BYTE FrameOffset : 4; // Frame Register offset (scaled)
UNWIND_CODE UnwindCode[1]; // Unwind codes array
/* UNWIND_CODE MoreUnwindCode[((CountOfCodes + 1) & ~1) - 1];
* union {
* OPTIONAL ULONG ExceptionHandler;
* OPTIONAL ULONG FunctionEntry;
* };
* OPTIONAL ULONG ExceptionData[]; */
} UNWIND_INFO, *PUNWIND_INFO;_UNWIND_INFO 구조체는 함수가 예외 상황에서 콜스택을 어떻게 복원할지를 정의한 메타데이터를 포함하며, 버전, 플래그, 함수 프롤로그의 크기, 언와인드 코드 수, 프레임 레지스터 및 그 오프셋, 그리고 복원 과정을 나타내는 UNWIND_CODE 배열로 구성된다. UNWIND_CODE 배열은 고정 길이가 아니며, CountOfCodes에 따라 추가적인 unwind 코드 및 선택적으로 예외 핸들러 주소를 포함할 수 있다.
typedef union _UNWIND_CODE {
struct {
UBYTE CodeOffset; // Offset in prolog
UBYTE UnwindOp : 4; // Unwind operation code
UBYTE OpInfo : 4; // Operation info
};
USHORT FrameOffset; // unsigned offset to a value in the local stack frame
} UNWIND_CODE, *PUNWIND_CODE;_UNWIND_CODE는 언와인드 동작을 정의하는 구조체로, 기본적으로 프롤로그 내 오프셋과 해당 위치에서 수행할 복원 동작의 종류 및 세부 정보로 이루어진다. 경우에 따라 이 구조체는 2바이트를 단일 FrameOffset으로 해석할 수 있으며, 특정 unwind 연산자에서 프레임 오프셋 정보를 필요로 할 때 사용된다.

함수가 스택 공간을 할당하거나 다른 함수를 호출하는 non-leaf 함수일 경우, 해당 코드 범위를 나타내는 RUNTIME_FUNCTION 엔트리를 .pdata 섹션에 기록하고, 그 엔트리가 참조하는 UNWIND_INFO(UNWIND_CODE) 구조체를 .xdata 섹션에 함께 정의해야 한다. 반면, 스택을 전혀 사용하지 않고 다른 함수도 호출하지 않는 leaf 함수의 경우에는 생략이 가능하다. 각각의 구조체는 .pdata와 .xdata 섹션에 기록되는 것이 기본이며, 이는 Microsoft의 링크 규칙과 운영체제 런타임에 의해 기대되는 표준 위치다. 하지만 이들 섹션은 절대적으로 고정된 것은 아니며, 다른 섹션에 배치될 수도 있다. 운영체제는 예외 처리 시 .pdata에 등록된 함수 범위를 기준으로 UNWIND_INFO의 위치를 RVA로 해석해 접근하기 때문에, .xdata가 아닌 다른 섹션에 존재하더라도 RVA 값만 정확하다면 기능적으로 문제는 발생하지 않는다.
1. 예외가 발생하면 운영체제는 RIP가 포함된 주소를 기준으로 .pdata 섹션에 저장된 RUNTIME_FUNCTION 테이블을 탐색하여 해당 함수의 예외 처리 정보를 조회한다.
2. 조회된 RUNTIME_FUNCTION 항목에 포함된 UnwindInfoAddress를 통해 .xdata 섹션에 위치한 UNWIND_INFO 구조체를 로드한다.
3. UNWIND_INFO는 프롤로그 길이, 프레임 레지스터 정보, 언와인드 코드 배열을 포함하며, OS는 이 코드를 역순으로 해석해 함수 진입 시점의 RSP 및 비휘발성 레지스터 값을 복원한다.
4. 복원된 스택 포인터와 레지스터 상태를 바탕으로 Caller(호출자) 함수의 리턴 주소(RIP)로 스택을 되돌리며, 이전 함수에 대해 동일한 과정을 반복한다.
5. 만약 UNWIND_INFO의 Flags 필드에 예외 핸들러의 존재가 명시되어 있으면, OS는 복원된 컨텍스트로 되돌아가지 않고 지정된 RVA에 위치한 핸들러로 제어를 전달하여 예외 처리를 수행한다.
이 절차는 예외 발생 시 콜스택을 정확히 복원하고, 필요한 경우 사용자 정의 핸들러로 제어를 안전하게 이전할 수 있도록 하기 위한 x64 예외 처리 메커니즘이다. 함수 단위로 기록된 Unwind Data는 스택 프레임을 역방향으로 추적하면서 Caller(호출자)의 컨텍스트를 재구성하는 데 필요한 최소한의 메타데이터를 제공하며, 이는 구조적으로 정렬된 데이터 기반의 예외 처리 흐름을 가능하게 함으로써 성능과 안정성 모두를 확보하는 데 기여한다.
7. 함수 호출 규약
x64 함수 호출 규약에 대한 자세한 내용은 https://kj0on.tistory.com/44 참고
8. 참고 문헌
[1] X64 Deep Dive, https://codemachine.com/articles/x64_deep_dive.html
[2] x64 호출 규칙, https://learn.microsoft.com/ko-kr/cpp/build/x64-calling-convention?view=msvc-170
[3] x64 스택 사용, https://learn.microsoft.com/ko-kr/cpp/build/stack-usage?view=msvc-170
[4] Why should data be aligned to 16 bytes for SSE instructions?, https://community.intel.com/t5/Software-Tuning-Performance/Why-should-data-be-aligned-to-16-bytes-for-SSE-instructions/td-p/1164004
[5] Debugging Stories: Stack alignment matters, https://research.csiro.au/tsblog/debugging-stories-stack-alignment-matters/
[6] What is the point of MOVAPS in x86 if it does the same as MOVUPS in modern computers?, https://stackoverflow.com/questions/79067215/what-is-the-point-of-movaps-in-x86-if-it-does-the-same-as-movups-in-modern-compu
[7] Instruction tables, https://agner.org/optimize/instruction_tables.pdf
[8] win64 Structured Exception Handling, https://www.tortall.net/projects/yasm/manual/html/objfmt-win64-exception.html
[9] Struct RUNTIME_FUNCTION, https://stackoverflow.com/questions/19808172/struct-runtime-function
'Reversing > Definition' 카테고리의 다른 글
| [Definition] 라이브러리 (Library) (0) | 2025.07.24 |
|---|---|
| [Definition] x32 ABI (0) | 2025.07.22 |
| [Definition] 64비트 함수 호출 규약 (64bit Calling Convention) (0) | 2025.07.19 |
| [Definition] 64비트 스택 프레임 (64bit Stack Frame) (0) | 2025.07.15 |
| [Definition] 32비트 함수 호출 규약 (32bit Calling Convention) (5) | 2025.07.14 |



