
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- __vectorcall
- pe format
- image section header
- 리치헤더
- 리버싱
- CodeEngn
- __cdecl
- Dos Stub
- 실행파일
- Reversing
- 파이썬
- Rich Header
- RVA
- Calling Convention
- rev
- 크랙미
- 프로그래머스
- __stdcall
- Python
- 32bit
- x32
- __fastcall
- ABI
- 코드엔진
- x64
- Programmers
- Image dos header
- crackme
- 함수 호출 규약
- stack frame
- Today
- Total
kj0on
[Definition] 64비트 스택 프레임 (64bit Stack Frame) 본문
0. x64 ABI
x64 ABI는 https://kj0on.tistory.com/47 참고
1. 정의
스택 프레임(Stack Frame)은 함수가 호출될 때 스택에 형성되는 하나의 논리적 메모리 블록으로, 해당 함수 실행에 필요한 정보를 일시적으로 보관해 주는 단위이다. 32비트 때와 유사한 목적을 가지지만, 64비트 함수 호출 규약과 CPU 설계 변화에 맞추어 구조와 규칙이 달라졌다.
2. 함수 프레임 (Function Frame)

함수의 시작에 붙는 패턴은 프롤로그(prologue), 끝 부분에 붙는 패턴은 에필로그(epilogue)로 구분할 수 있으며, 직접 작성한 코드의 로직은 두 패턴 사이의 바디(body)에 위치하게 된다. 이러한 공통된 틀은 컴파일 단계에서 컴파일러가 자동으로 삽입한다. 덕분에 모든 함수가 일관된 스택 프레임을 유지할 수 있게 되며 중첩 호출 상황에서도 데이터와 복귀 주소가 안전하게 보호된다. x86에서는 함수의 프롤로그와 에필로그가 상대적으로 정형화된 형태로 나타난다. 그러나 x64에서는 프롤로그와 에필로그의 형태가 하나로 고정되지 않으며, 함수의 특성이나 컴파일 옵션, 최적화 여부 등에 따라 여러 가지 방식으로 다양하게 구성될 수 있다.
Frame Pointer Omission
Unlike the X86 CPU where the EBP register is used to access parameters and local variables on the stack, X64 functions do not make use of the RBP register for this purpose i.e. do not use the EBP register as a frame pointer. Instead, it uses the RSP register both as a stack pointer and a frame pointer, more on how this works in the next topic. So, on X64 the RBP register is now freed up from its stack duties and can be used as a general purpose register. An exception to this rule are functions that use alloca() to dynamically allocate space on the stack. Such functions will use the RBP register as a frame pointer, as they did with EBP on the X86.
Stack Pointer based local variable access
On the X86 CPU, the most important function of the frame pointer (EBP) register is to provide access to stack based parameters and local variables. As discussed earlier, on the X64 CPU, the RBP register does not point to the stack frame of the current function. So on X64, it is the RSP register that has to serve both as a stack pointer as well as a frame pointer. So all stack references on X64 are performed based on RSP. Due to this, functions on X64 depend on the RSP register being static throughout the function body, serving as a frame of reference for accessing locals and parameters. Since push and pop instructions alter the stack pointer, X64 functions restrict push and pop instructions to the function prolog and epilog respectively. The fact that the stack pointer does not change at all between the prolog and the epilog is a characteristic feature of X64 functions, as shown in Figure 3.
x86에서는 EBP가 스택의 기준점이 되어 매개변수와 지역 변수를 안정적으로 참조하지만, x64에서 RBP는 더 이상 프레임 포인터로 사용되지 않는다(다른 레지스터와 마찬가지로 범용 레지스터로 사용될 수 있음). RBP가 더 이상 현재 프레임을 가리키지 않으므로 RSP가 스택 포인터와 프레임 포인터 두 역할을 동시에 맡아야 한다. 이 때문에 모든 스택 접근은 RSP를 기준으로 이루어지고, push, pop 명령어는 스택 포인터를 변경하므로 x64 함수는 해당 명령어를 함수 프롤로그와 에필로그로 제한된다. 단, alloca()를 사용하여 스택 공간을 동적으로 할당하는 함수는 예외로 x86의 EBP와 마찬가지로 RBP 레지스터를 프레임 포인터로 사용한다.

추가적으로 알아야 할 점은 특정 조건에서는 다시 RBP가 프레임 포인터 역할을 수행할 수 있다는 것이다. 즉, 모든 스택 접근이 반드시 RSP를 기준으로 이루어지는 것은 아니며, 상황에 따라 RBP를 기준점으로 사용하는 x86 방식이 다시 등장할 수 있다. 이는 디버깅을 용이하게 하고 RSP가 함수 바디에서 변동될 가능성이 있는 상황에서 안정적인 기준점 역할을 하기 위함이다. 따라서 x64에서 RBP는 항상 생략되는 것도, 항상 사용되는 것도 아닌 선택적인 옵션에 해당한다는 사실을 이해해야 한다.
| 패턴 | 프롤로그 시퀀스 | 에필로그 시퀀스 |
| Opt-Full | (없음) | (없음) |
| Opt-Mid | sub rsp, imm | add rsp, imm ret |
| Leaf | push rbp sub rsp, imm mov rbp, rsp |
lea rsp, [rbp+imm] pop rbp ret |
| Non-Leaf | push rbp sub rsp, imm+20h lea rbp, [rsp+20h] |
lea rsp, [rbp+imm] pop rbp ret |
x64 함수 프롤로그, 에필로그는 최적화 수준 및 함수 호출 여부에 따라 대표적으로 네 가지 패턴으로 분류할 수 있다. 최적화가 활성화된 경우에는 Opt-Full 또는 Opt-Mid 패턴이 나타난다. 반면, 최적화가 꺼져 있거나 디버깅을 위한 정보가 필요한 경우에는 Leaf 또는 Non-Leaf 패턴이 등장하며, RBP를 프레임 포인터로 복원한다. 다만 이러한 네 가지 분류 외에도 함수의 구조나 요구사항에 따라 다양한 형태의 프롤로그, 에필로그가 존재할 수 있으며, 이는 내부적 조건에 따라 달라진다. 따라서 실제 컴파일 결과에서는 대표적인 패턴을 벗어난 변형된 구조가 나타날 수 있다. 특히 위의 분류는 주관적 판단에 의한 것이므로, 전반적인 컴파일러 구현이나 ABI 사양을 완전히 대변한다고 보기에는 한계가 있다.
| 함수, 최적화 | 패턴 |
| Leaf function, /Od | Leaf |
| non-Leaf function, /Od | Non-Leaf |
| Leaf alloca function, /Od | Leaf |
| non-Leaf alloca function, /Od | Non-Leaf |
| Leaf function, /O1 | Opt-Full |
| non-Leaf function, /O1 | Opt-Full |
| Leaf alloca function, /O1 | Leaf |
| non-Leaf alloca function, /O1 | Non-Leaf |
최적화 수준과 함수 형태에 따라 프롤로그 패턴은 다르게 나타난다. /Od처럼 최적화가 꺼진 경우 Leaf, Non-Leaf 패턴을 따른다. /O1과 같이 최적화가 적용된 경우에는 Opt-Full 패턴으로 축소되며 이는 작성 코드에 따라 달라진다. main의 경우 Opt-Mid 패턴이 나타났다. 하지만 alloca()를 사용하여 스택 공간을 동적으로 할당하는 함수는 예외로 x86의 EBP와 마찬가지로 RBP 레지스터를 프레임 포인터로 사용한다.
3. 스택 프레임 (Stack Frame)
3-1. 코드 및 스택 구조 개요
#include <stdio.h>
int to_seconds(int hour, int minute, int second) {
int result_hour = 0;
int result_minute = 0;
int result_second = 0;
int result_total = 0;
result_hour = hour * 3600;
result_minute = minute * 60;
result_second = second;
result_total = result_hour + result_minute + result_second;
return result_total;
}
int main() {
int h = 1;
int m = 30;
int s = 15;
int total = to_seconds(h, m, s);
printf("Total seconds: %d\n", total);
return 0;
}위의 코드는 시, 분, 초를 각각 초 단위로 환산한 뒤 합산하는 단순한 흐름으로 되어 있다. 해당 코드를 토대로 스택 프레임이 어떻게 생성되고 소멸하는지를 단계별로 살펴본다.
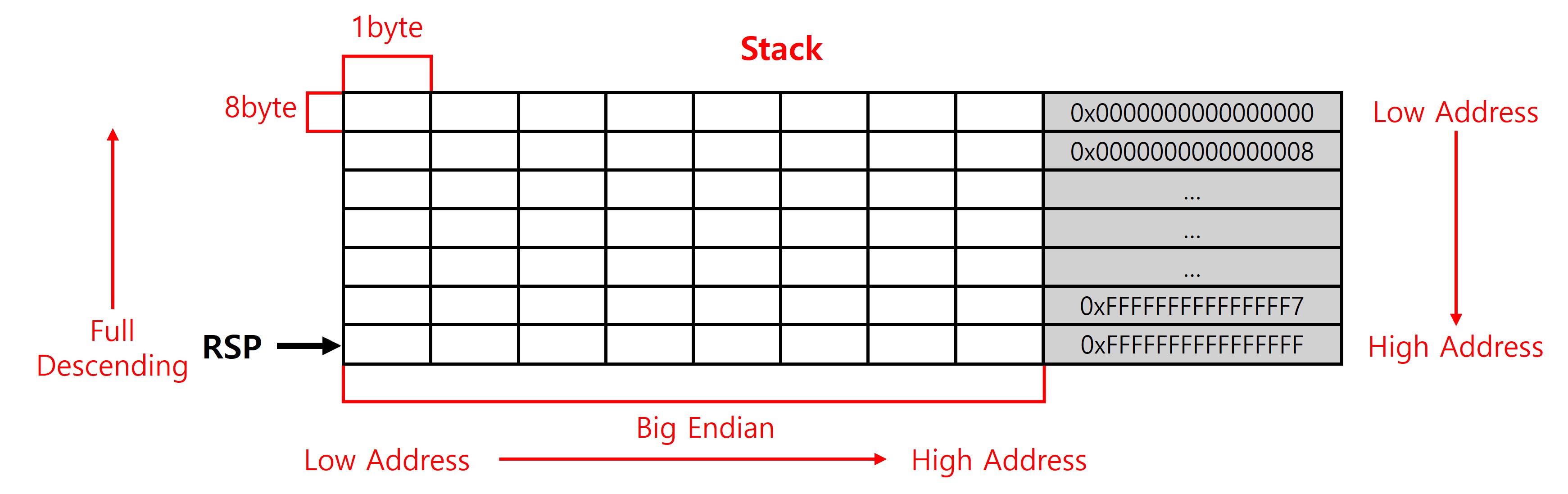
x64 환경을 고려해 스택은 Full Descending 방식으로 동작하므로, ESP 레지스터는 데이터를 저장할 때마다 더 낮은 주소로 이동한 뒤 해당 위치에 값을 기록한다. 낮은주소와 높은 주소의 위치는 위와 같으며 주소의 간격은 8byte다. 데이터를 기록할 때는 가독성을 고려해 빅엔디언 방식을 적용한다.
3-2. 스택 프레임 분석 (Leaf & Non-Leaf)

main함수 진입 후, 스택의 초기 상태는 위와 같다. 함수 진입 전, call main의 push rip 명령어로 인해 스택에는 main함수 종료 후 되돌아 갈 주소가 저장되어 있다. 32비트와의 차이점은 64비트 주소 지정 기능, 일반 용도로 사용하는 16개의 64비트 레지스터를 사용한다는 점이다(https://learn.microsoft.com/ko-kr/cpp/build/x64-software-conventions?view=msvc-170).

최적화를 적용하지 않은 Debug 빌드에서 main 함수는 to_seconds 함수를 호출하므로 Leaf 함수가 아니며, 이에 따라 Non-Leaf 패턴이 나타난다. 이 패턴의 대표적인 특징은 함수 진입 시 push rbp 명령어를 사용해 현재 RBP를 스택에 저장하고, 이후 lea를 통해 기준점을 설정하는 것이다. 다만 x64 환경에서 push rbp는 ABI의 필수 사항이 아니며, 디버깅의 편의성을 위해 컴파일러가 삽입하는 경우가 많다. 실제로 최적화가 활성화된 Release 빌드에서는 이러한 프레임 포인터 설정이 생략되는 경우가 일반적이며, 이때는 RSP 기반으로만 지역 변수 접근이 이뤄지고 prologue 자체가 간결화되는 경향이 있다.

sub rsp, imm 명령은 함수가 실행되는 동안 사용할 영역을 한꺼번에 확보하는 명령이다. 이 영역엔 로컬 변수, 인자, 홈 파라미터 등이 포함된다. x32와 마찬가지로 이 명령어는 단순히 영역 확보 이상의 의미를 갖는다. x32에서는 함수 본체에서 push 명령이 자주 사용되어 로컬 영역과 충돌 가능성이 있었지만, x64는 본체에서 push를 사용하지 않기 때문에 정적 공간 확보만으로 모든 지역 데이터를 처리할 수 있게 한다. 따라서 x32에서와는 조금 다른 의미를 갖는다. 호출 직전의 call 명령어로 인해 발생한 push rip, 그리고 선택적으로 존재하는 push rbp로 인해 RSP가 어긋난 상황을 보정해 16byte로 재정렬하는 역할을 수행한다. 또한 이러한 정렬과 구조는 언와인드 데이터(unwind data)를 위한 고정된 프롤로그 패턴을 형성하며, 예외 발생 시 호출 스택 복구에 사용된다. 그리고 함수를 호출할 때, Caller(호출자)의 로컬 영역과 그 다음의 함수에서 사용하는 로컬 영역, 그리고 리턴 주소를 겹치지 않도록 하는 역할 또한 수행한다.

lea rbp, imm 명령은 인자와 로컬 영역을 구분하는 기준점을 설정하는 역할을 한다. 다만, x64에서는 RBP를 프레임 포인터로 사용하는 것이 필수적이지 않으며, RBP를 범용 레지스터로 활용해 연산 성능을 높이기도 한다. 이 때문에 RBP를 명시적으로 설정하지 않고 RSP 기준으로 스택 참조를 수행하는 함수들도 존재한다. 그럼에도 이 명령이 포함되는 이유는 디버깅을 고려해 명확한 프레임 경계를 제공하거나 스택 구조를 추적할 수 있도록 일관된 기준을 제공할 수 있기 때문이다. 또한 예외 처리 시 언와인드 정보를 쉽게 구성하려는 목적에서 이 명령이 삽입되는 경우도 많다. 결국 이 명령은 컴파일러의 정책 또는 디버깅 친화성을 위한 선택적 구성 요소로 해석해야 한다.

이후 body부분의 코드에서는 RBP를 기준으로 시간(h), 분(m), 초(s) 값을 로컬 변수 영역에 저장하며, 이때 push 명령 대신 mov 명령을 사용하여 직접 스택에 값을 할당한다. 이는 함수 진입 시 고정된 크기의 프레임을 미리 확보한 상태에서 RSP를 변경하지 않음으로써, 스택의 16byte 정렬을 유지하려는 목적에 기반한다. 그리고 RBP는 섀도우 스페이스를 피해 설정되어 있기 때문에 해당 프레임에서 인자 전달용 공간과 로컬 변수 공간이 명확히 분리되며 값들의 충돌 없이 안전하게 저장된다. 그러나 이러한 구조는 이전에도 설명했듯이 선택적으로 활용되는 것으로, 필수적인 요소는 아니다. RSP를 기준으로 해도 동일한 동작을 구현할 수 있으며, 최적화 적용 시 실제로 RSP 상대 주소만으로 스택을 운용하는 방식이 보다 일반적으로 채택된다.

to_seconds 함수를 호출하기 전, 각각의 로컬 변수(h, m ,s)를 레지스터에 담고 있다. x64 함수 호출 규약에 따라 정수형 인자는 순서대로 ECX, EDX, R8, R9 레지스터를 통해 전달되며, 이 예제에서는 인자가 3개이므로 ECX, EDX, R8이 사용된다. x32환경과 달리, x64에서는 하나의 고정된 호출 규약이 적용되어 함수마다 호출 방식이 달라지지 않는다. 이때, 인자의 자료형에 따라 레지스터 그룹이 구분되는데, 정수형은 위와 같은 범용 레지스터, 부동소수점형은 XMM0~XMM3 등의 레지스터를 통해 전달된다.

call to_seconds 명령을 통해 함수 호출 직전, 제어 흐름이 되돌아올 위치인 다음 명령어의 주소 0x0000000140011ADF를 스택에 push하여 저장한다. 이는 호출된 함수가 작업을 마친 후 ret 명령을 통해 복귀할 수 있도록 하기 위한 동작으로 x32와 동일한 메커니즘을 사용한다. 이후 호출되는 함수(to_seconds)의 프롤로그 부분에서 16byte 정렬을 맞추는 동작(sub rsp, imm)이 포함되어 있기 때문에 body에서 push가 가능하다. 이처럼 함수를 호출하는 동작은 프롤로그 단계에서 정렬이 보장되어 있기 때문에 body 내부에서도 제한적으로 push를 사용할 수 있다.

to_seconds 함수의 프롤로그 부분에서 인자로 전달받은 레지스터 ECX, EDX, E8을 다시 스택에 저장하는 동작을 한다. 이 동작은 인자의 백업을 위해 사용될 수도 있지만, 해당 예제 코드에서는 최적화를 적용하지 않았기 때문에 디버깅 용이성을 위해 나타난 코드이다. 이 영역은 main에서 미리 확보한 Shadow Space 영역이다.
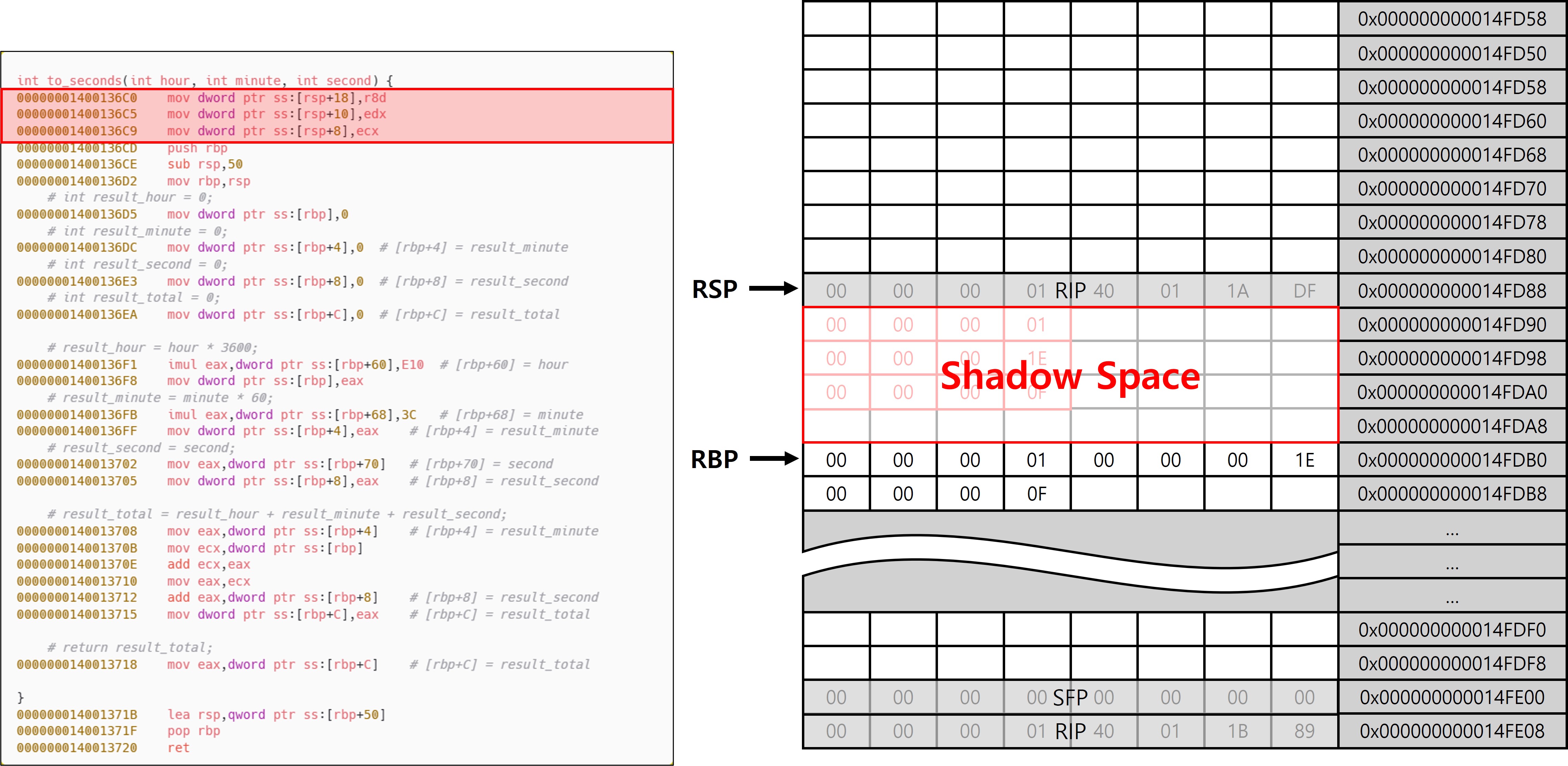
x64 ABI에 따르면 Shadow Space는 함수를 호출하기 전, Caller(호출자)가 필수적으로 확보해야 하는 공간이다. 이 동작은 main의 프롤로그 부분에서 sub rsp, imm을 할 때 확보된다. 따라서 imm의 최소값은 Shadow Space 영역의 크기인 32byte로 제한된다. Callee(피호출자)는 이 공간을 상황에 따라 유연하게 활용할 수 있다.

to_seconds 함수는 Leaf 함수이기 때문에 Leaf 패턴이 나타나는 것을 확인할 수 있다. 이때 사용되는 push rbp는 프레임 포인터를 보존하려는 관례 혹은 디버깅에 따른 것으로, 앞서 설명한 것처럼 반드시 필요한 절차는 아니며 RSP 기준으로도 동일한 동작을 구현할 수 있다.
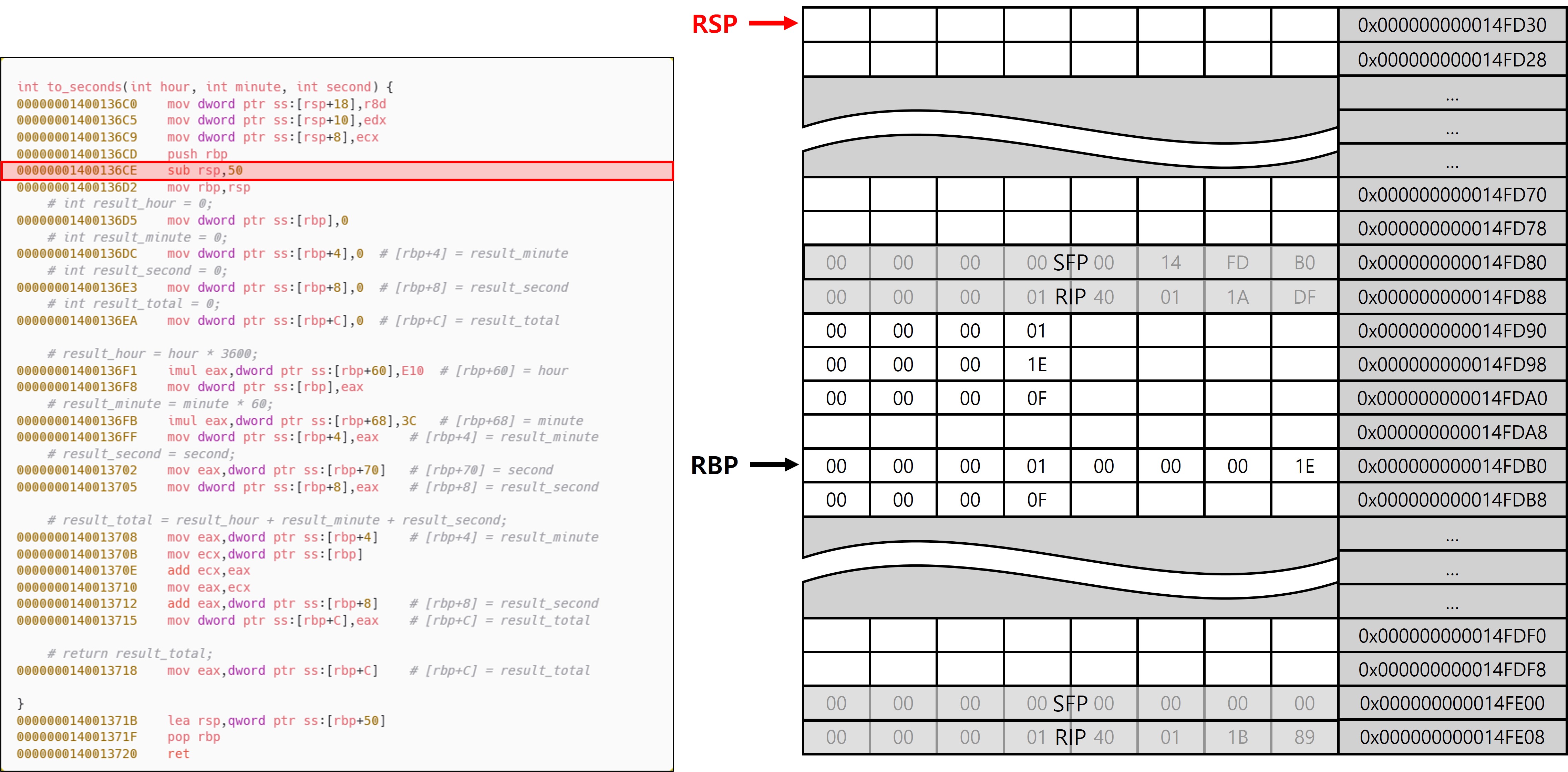
이후 to_seconds 함수의 프롤로그에서는 sub rsp, imm 명령을 통해 함수 내부에서 사용할 로컬 변수 공간을 확보하고 있다. 이는 단순한 데이터 저장 목적을 넘어, main 함수와 마찬가지로 스택의 16byte 정렬을 유지하고 예외 처리 시 언와인드(unwind) 정보를 정형화하기 위한 것이다.

다만 main 함수와의 차이점은 to_seconds가 Leaf 함수라는 점에 있다. Leaf 함수는 내부에서 다른 함수를 호출하지 않기 때문에, Shadow Space를 추가로 확보할 필요가 없으며, 호출 인자와 로컬 변수 영역을 분리할 필요도 없다. 이로 인해 프레임 구성에서도 차이가 발생하며, 그 결과 서로 다른 패턴(Leaf, Non-Leaf)이 등장하는 것이다. to_seconds에서는 함수 진입 직후 설정된 RSP와 RBP가 동일한 위치를 가리키고 있는 것을 확인할 수 있는데, 이는 to_seconds가 Leaf 함수이기 때문이다. 또한 x32에서 EBP가 SFP를 가리키고 있는 구조와 전혀 다른 모습이 나타난다는 것을 확인할 수 있다(이 동작이 가능한 이유는 이후 에필로그에서 설명).
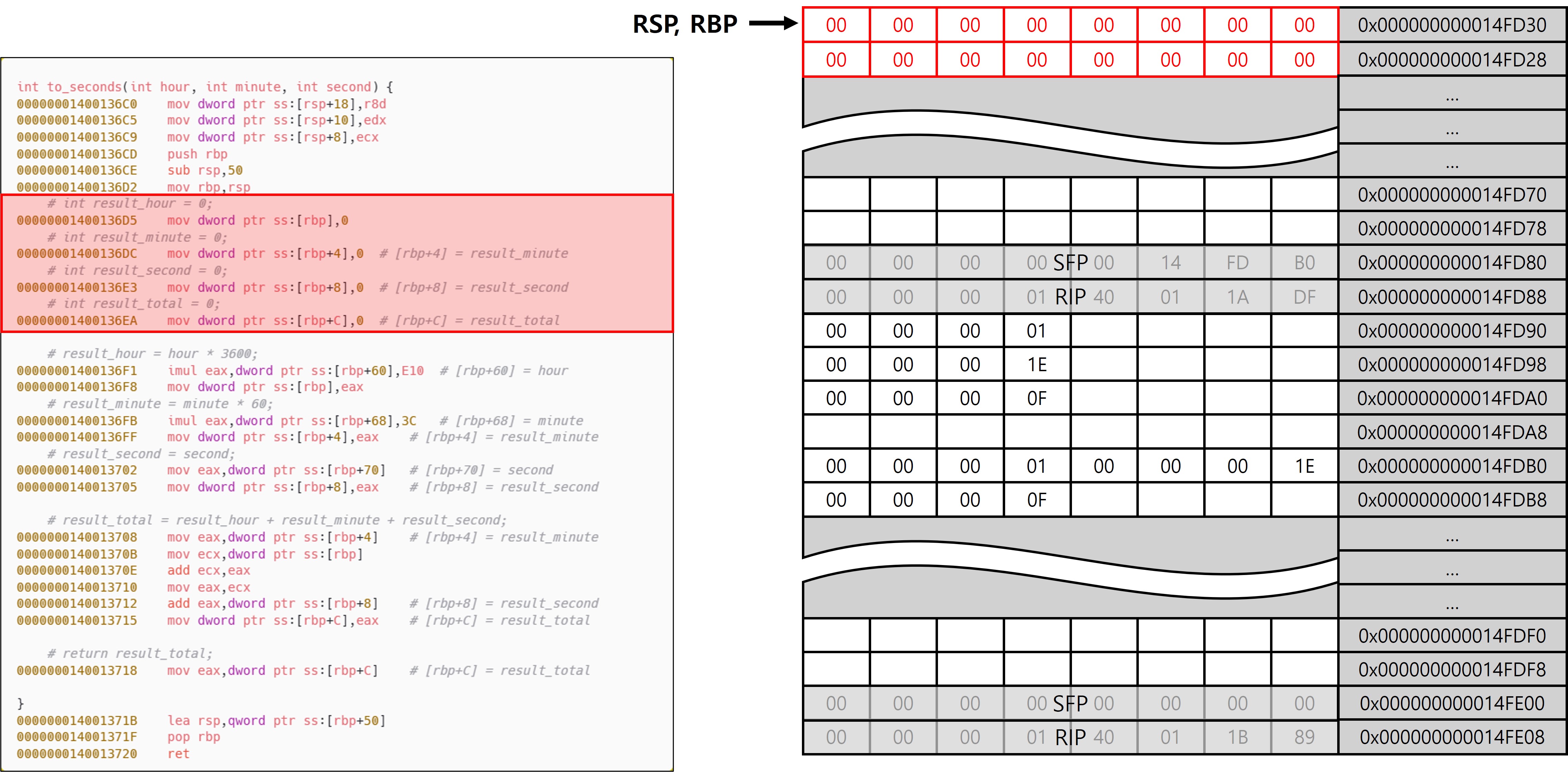
이후 EBP를 기준으로 로컬 변수를 초기화 하는 동작을 수행한다. to_seconds 함수에서 사용하는 로컬 변수인 result_hour, result_minute, result_second, result_total의 값을 0으로 초기화 한다.
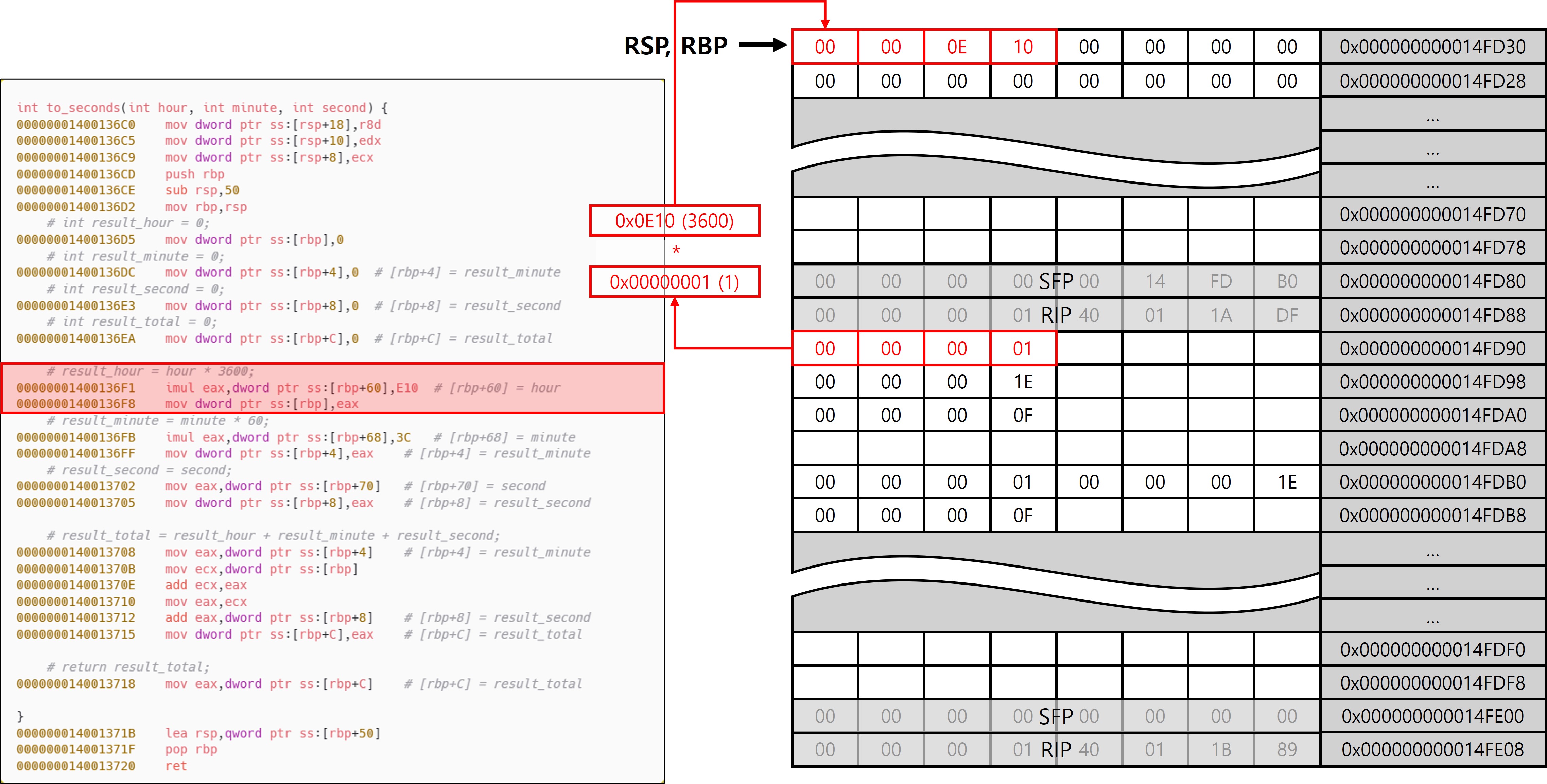
시간(h)를 초(s)로 변환하는 코드로, imul을 통해 그 연산 결과를 EAX에 담는다. 이때 사용하는 인자는 Shadow Space에 백업한 스택을 참조한다. 이는 x64 함수 호출 규약에서 레지스터를 활용한다는 이점이 없어지는 것 처럼 보인다(레지스터로 전달한 인자를 다시 스택에 담고 그 스택에 저장된 값을 참조하기 때문). 하지만 이는 최적화를 사용하지 않고 Debug /Od로 빌드했기 때문이다. 컴파일 옵션에 따라 인자를 활용하는 방식에는 차이가 발생한다. 따라서 인자를 백업할 필요가 없는 상황이라면 레지스터 값을 바로 참조해서 연산을 진행하기도 한다.
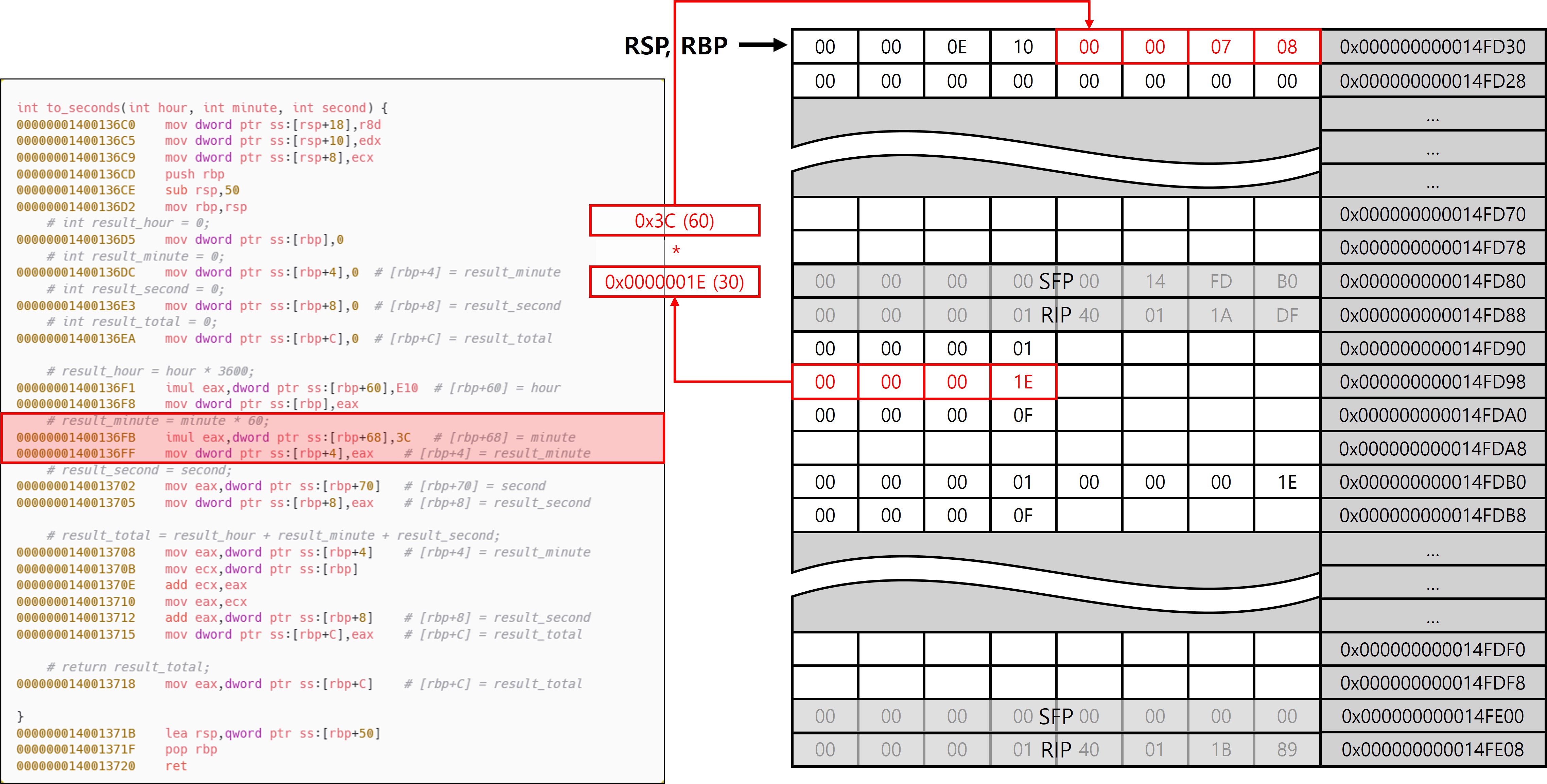
분(m)을 초(s)로 변환하는 코드로, 이전과 같이 스택에 백업한 값을 사용한다. 연산 결과를 to_seconds의 로컬 변수 영역에 저장한다.
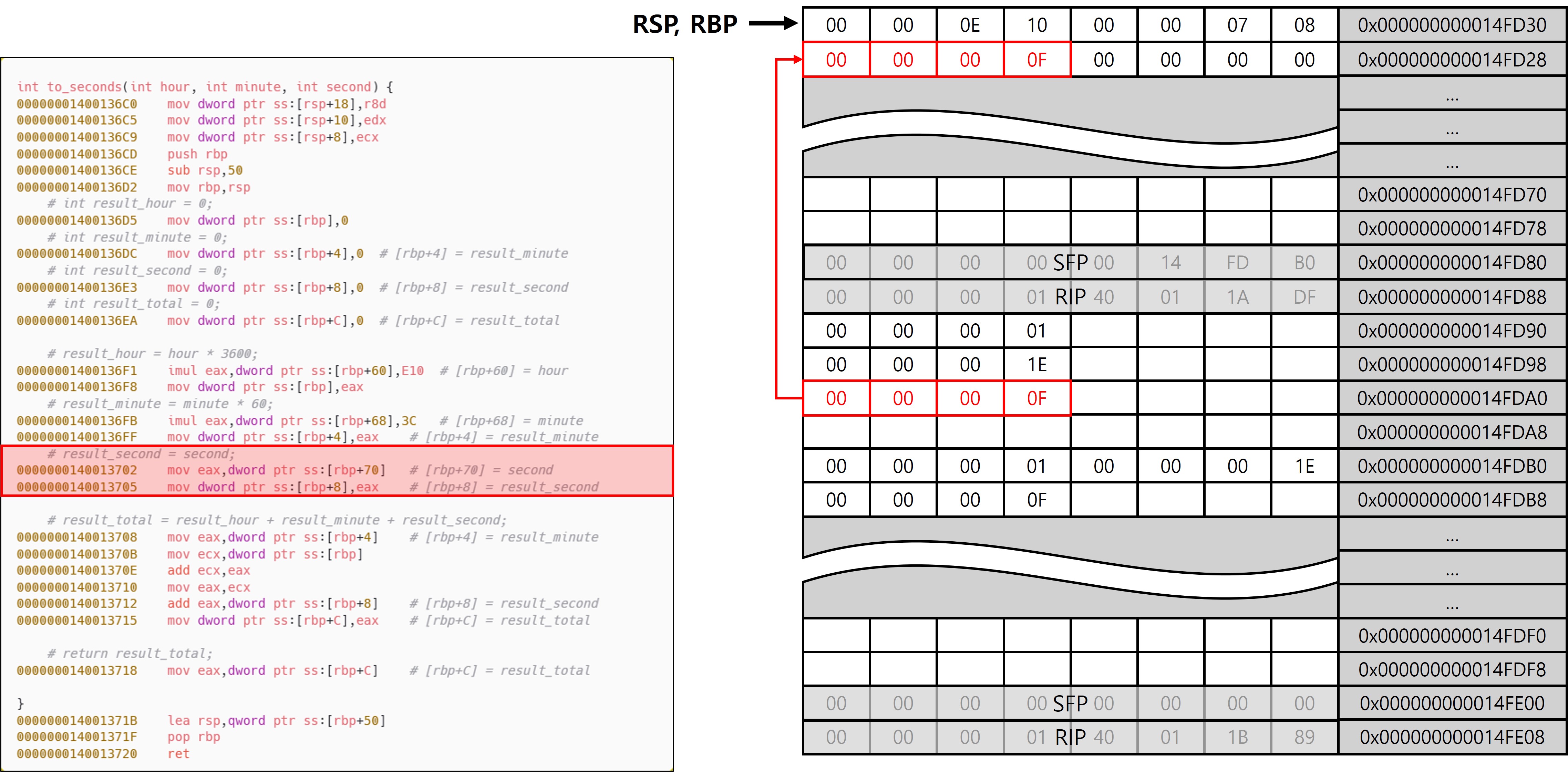
초(s)를 읽어서 기록하는 코드로, 이전과 같이 스택에 백업한 값을 사용한다. 연산 결과를 to_seconds의 로컬 변수 영역에 저장한다.

앞선 연산 결과를 모두 더해주는 코드로, 시간(h), 분(m), 초(s)를 모두 합산한 결과를 to_seconds의 로컬 변수 영역에 저장한다.

return을 통해 함수의 연산 결과 값이 호출자(main)에게 전달 될 수 있도록 한다. 이는 주로 EAX 레지스터에 결과를 저장하는 방식으로 이루어진다.
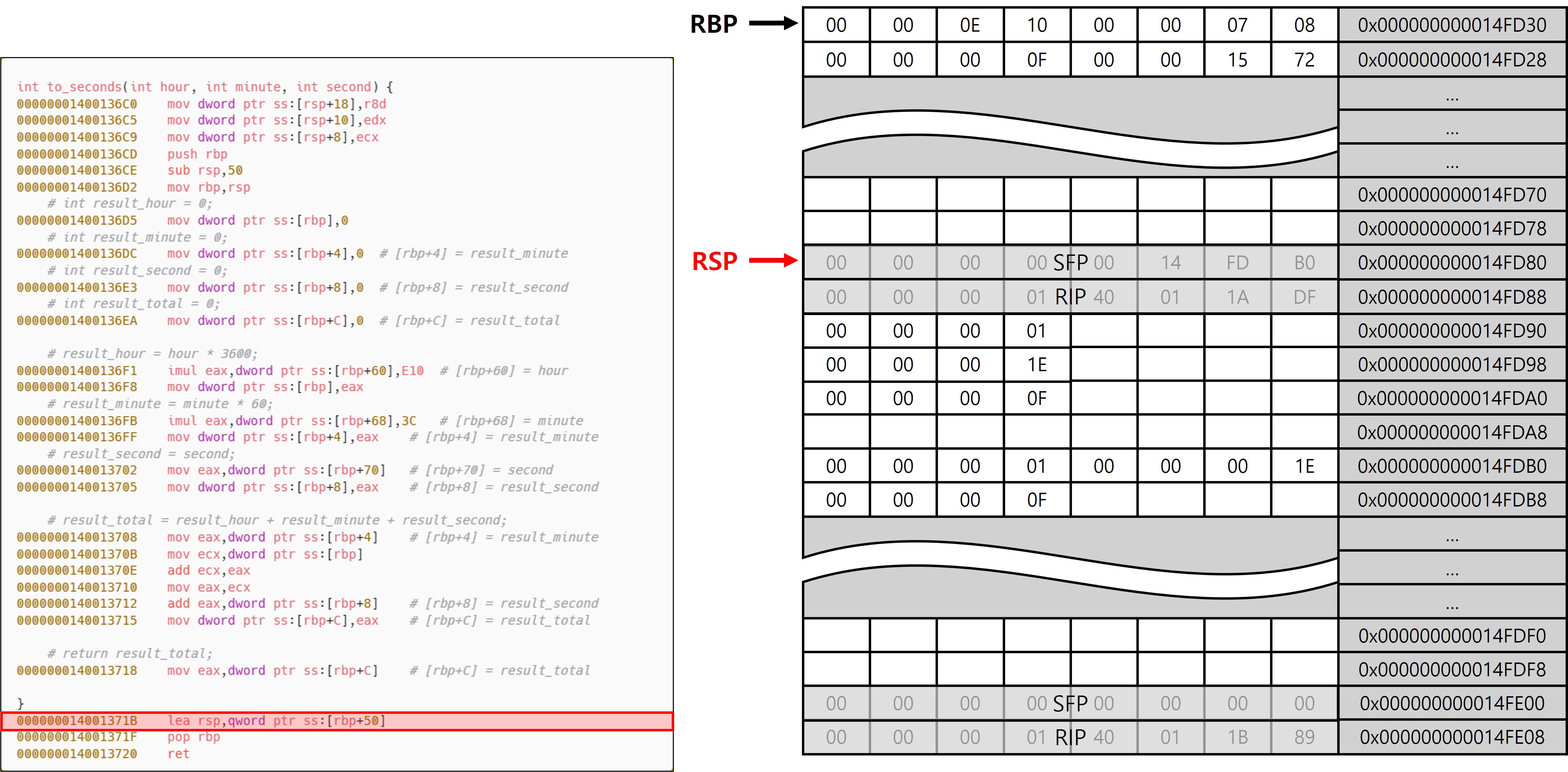
[이미지15]에서 확인할 수 있듯, RBP가 SFP를 가리키지 않아도 복구가 가능한 이유는 에필로그에 위치한 lea rsp, imm 명령을 통해 스택 포인터를 정확히 원래 위치로 되돌릴 수 있기 때문이다. 이는 RBP를 프레임 포인터로 사용하지 않고 범용 레지스터로 활용하는 함수에서 자주 나타나는 방식으로, 프롤로그에서 sub rsp, 0x50과 같이 확보한 스택 크기만큼을 에필로그에서 정확히 더해주는 구조를 통해 RSP를 복구한다. 다시 말해, 복귀 지점의 RSP는 최초 확보한 스택 공간 크기만큼만 조정하면 되기 때문에, 굳이 SFP를 유지하거나 저장할 필요 없이 프레임 복구가 가능해지는 것이다. 이러한 구조는 x64 ABI의 특성에 기반한다. x64에서는 함수 body 구간에서 RSP가 항상 16byte 정렬을 유지해야 하며, 이로 인해 push나 pop과 같이 RSP를 변경하는 명령은 프롤로그 또는 에필로그에서만 제한적으로 사용된다. 즉, 함수가 실행되는 동안에는 RSP가 고정된 구조로 유지되며, 컴파일러는 이를 전제로 안전한 스택 복구 코드를 생성할 수 있다. 반면 x32에서는 함수 body에서도 자유롭게 push와 pop이 사용되므로, ESP의 값이 body 구간에서 지속적으로 변동될 수 있다. 이로 인해 프롤로그에서 sub esp, imm로 확보한 크기가 에필로그 시점에서는 유효하지 않을 수 있으며, 정확한 복구를 위해 항상 고정된 기준점인 EBP가 필요하게 된다. 따라서 x64에서는 RSP를 기반으로 프레임 복구가 가능하지만, x32에서는 ESP의 변동 가능성 때문에 반드시 EBP를 저장하고 이를 통해 복구하는 방식이 채택되는 것이다. 이 차이는 함수 호출 규약과 ABI 정렬 조건에서 기인하며, 컴파일러는 이러한 규칙을 바탕으로 스택 복구용 상수 값을 컴파일 타임에 고정된 값으로 삽입하게 된다. 이 외에 가장 핵심적인 부분은 x64에서 언와인드 테이블(.pdata/.xdata)에 기록된 프롤로그 메타데이터와 RSP만으로도 예외 처리 및 디버깅 단계에서 완전한 스택 복원이 가능하다는 것이다.
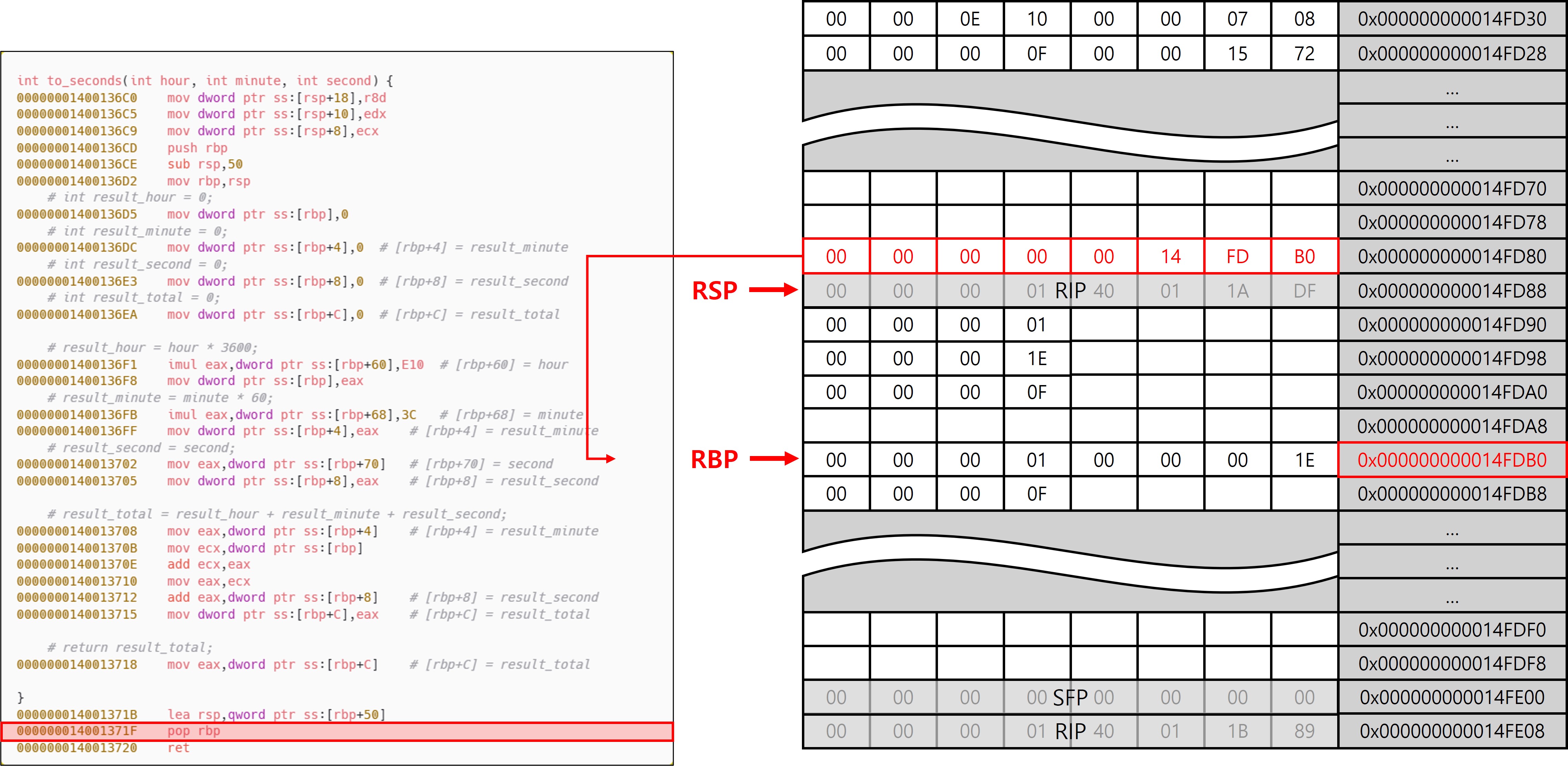
pop rbp 명령은 함수 종료 시점에서 스택 상단에 저장된 이전 RBP 값을 꺼내어 현재 RBP에 복원함으로써 호출자의 프레임 포인터를 재설정하는 역할을 한다. 동시에 이 동작으로 RSP는 리턴 주소(RIP)를 가리키는 위치로 이동하게 되며, 이전의 상태로 돌아갈 준비를 마치게 된다. 이는 RBP를 프레임 포인터로 사용할 때 일반적으로 나타나는 전형적인 에필로그 패턴이다. 반면 RBP를 프레임 포인터로 사용하지 않고 범용 레지스터로 활용하는 경우에는 push rbp나 pop rbp 같은 동작이 생략된다. 대신 에필로그에서는 lea rsp, imm 명령을 통해 RSP를 리턴 주소(RIP)가 저장된 위치로 이동하는 동작을 한다. 따라서 곧바로 ret 명령 동작이 가능해진다.
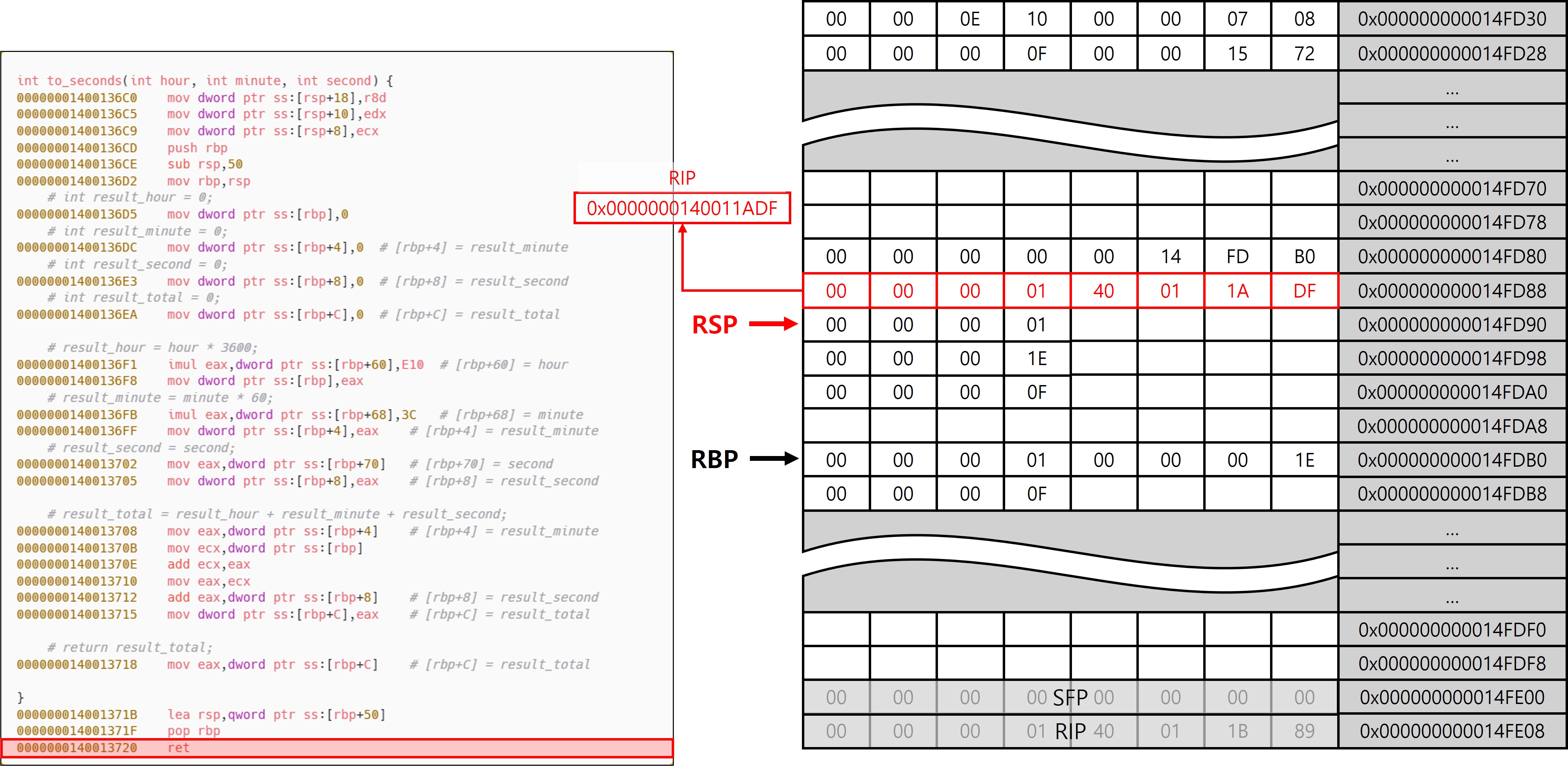
ret 내부 동작으로 pop rip를 수행하기 때문에 함수 호출 전, 스택에 저장한 값(to_seconds 호출 이후 주소)을 RIP에 저장해서 제어 흐름을 정확히 원래 위치로 되돌린다.

to_seconds 함수의 연산 결과를 return 명령어를 통해 EAX 레지스터에 저장해 놨기 때문에, EAX를 참조해서 main의 로컬 변수인 total에 저장한다.

printf 호출 시에도 마찬가지로, 먼저 포맷 문자열과 인자들이 스택에 적재되고, RIP와 SFP(선택적)가 차례로 스택에 저장된다. 이어서 printf 내부의 프롤로그가 새로운 스택프레임을 설정하고, 바디에서 포맷 문자열을 해석해 콘솔(cmd) 창에 지정된 문자열을 출력한다. 에필로그 단계에서 RSP와 RBP(선택적)를 원래 상태로 복원한다. 마지막으로 ret이 실행되면 printf를 호출 할 때 저장된 RIP가 복원되어 호출 지점으로 되돌아가면서 제어가 다시 main 함수로 넘어온다.
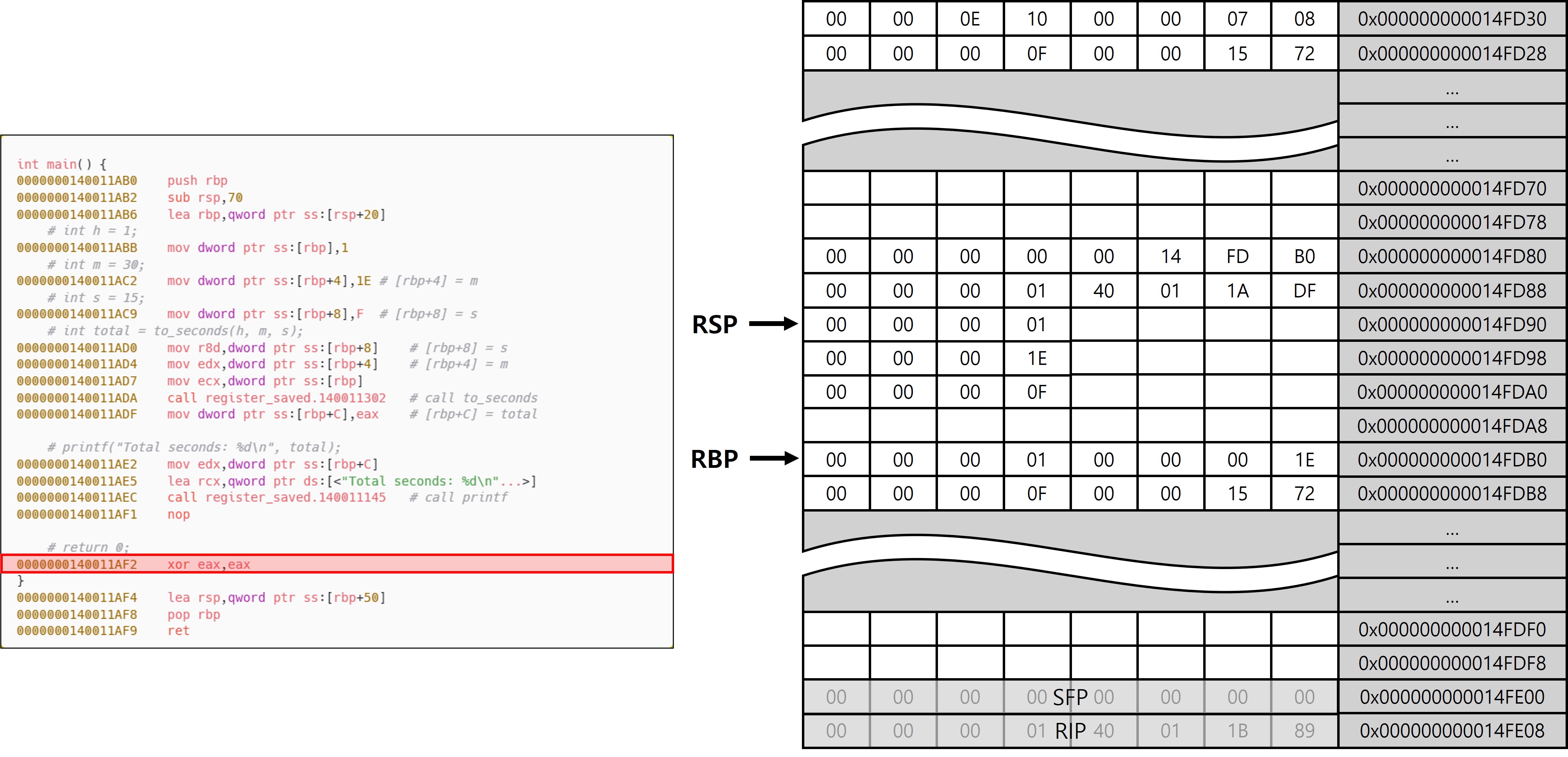
xor eax, eax 명령은 레지스터 EAX의 값을 0으로 초기화하는 역할을 한다. 주로 return 0; 구문을 컴파일할 때 생성되며, 프로그램이 정상적으로 종료되었음을 Caller(호출자)에 알리는 용도로 쓰인다.

main의 에필로그 동작을 살펴보면 to_seconds 함수의 에필로그에서는 프롤로그에서 사용한 sub rsp, imm 명령과는 다른 방식으로 스택을 정리하고 있다. 이는 단순히 확보한 크기가 다르기 때문이 아니라 RBP를 기준으로 스택을 복구하기 때문에 나타나는 현상이다. 예제에서 main 함수는 Non-Leaf 함수로, 다른 함수를 호출하기 때문에 Shadow Space를 포함해 스택 공간을 확보한다(이 자체가 스택 정리 방식에 영향을 준 것은 아님). 중요한 점은 해당 예제에서 RBP를 프레임 포인터로 사용하고 있으며, 이로 인해 인자와 로컬 변수의 경계를 설정 하기 위해 RBP가 RSP보다 0x20 높은 위치, 즉 rsp + 0x20에 설정된다는 것이다. 이후 함수 종료 시에는 RBP를 기준으로 RSP를 복원하기 때문에, lea rsp, [rbp + 0x50]과 같은 형태로 정리하게 되고, 결과적으로 이는 처음 프롤로그에서 확보한 공간인 0x70과 동일한 크기를 복구하게 된다. 반면 RBP를 사용하지 않고 RSP를 기준으로 스택을 운용하는 함수에서는, 프롤로그에서 sub rsp, 0x70으로 확보한 만큼 에필로그에서 add rsp, 0x70으로 정확히 복구하는 방식이 사용된다. 따라서 x64에서 Non-Leaf 함수가 RBP를 활용할 경우, 스택 정리는 RBP + offset을 통해 간접적으로 수행되며, 그 차이는 RBP가 설정되는 위치를 기준으로 발생한다.

pop rbp로 SFP를 다시 RBP에 복원한다. RBP를 프레임 포인터로 사용하는 경우에 포함되는 패턴이다.
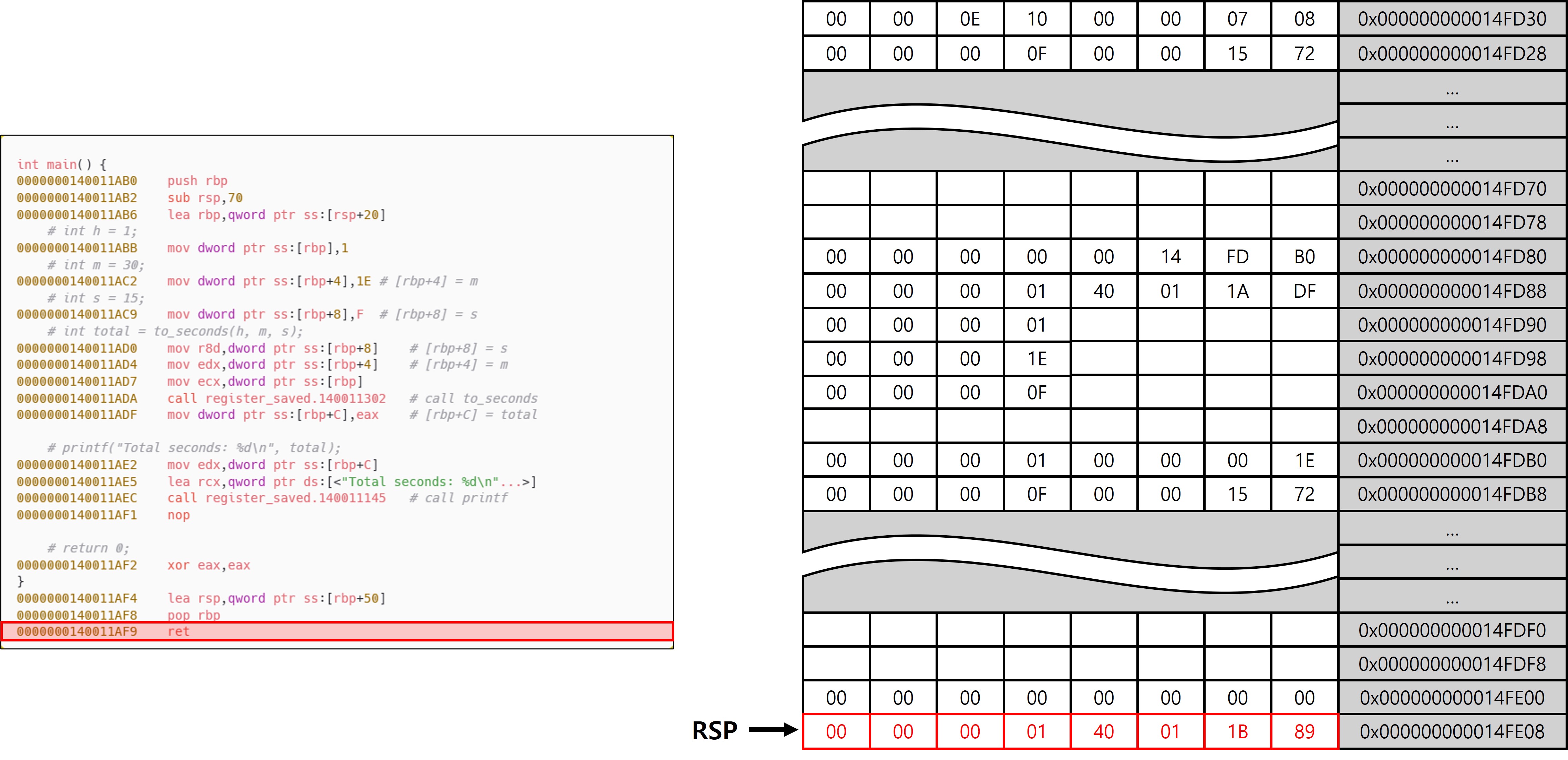
ret의 pop rip의 동작을 통해 제어 흐름을 main 함수 호출 직후 위치로 변경한다.
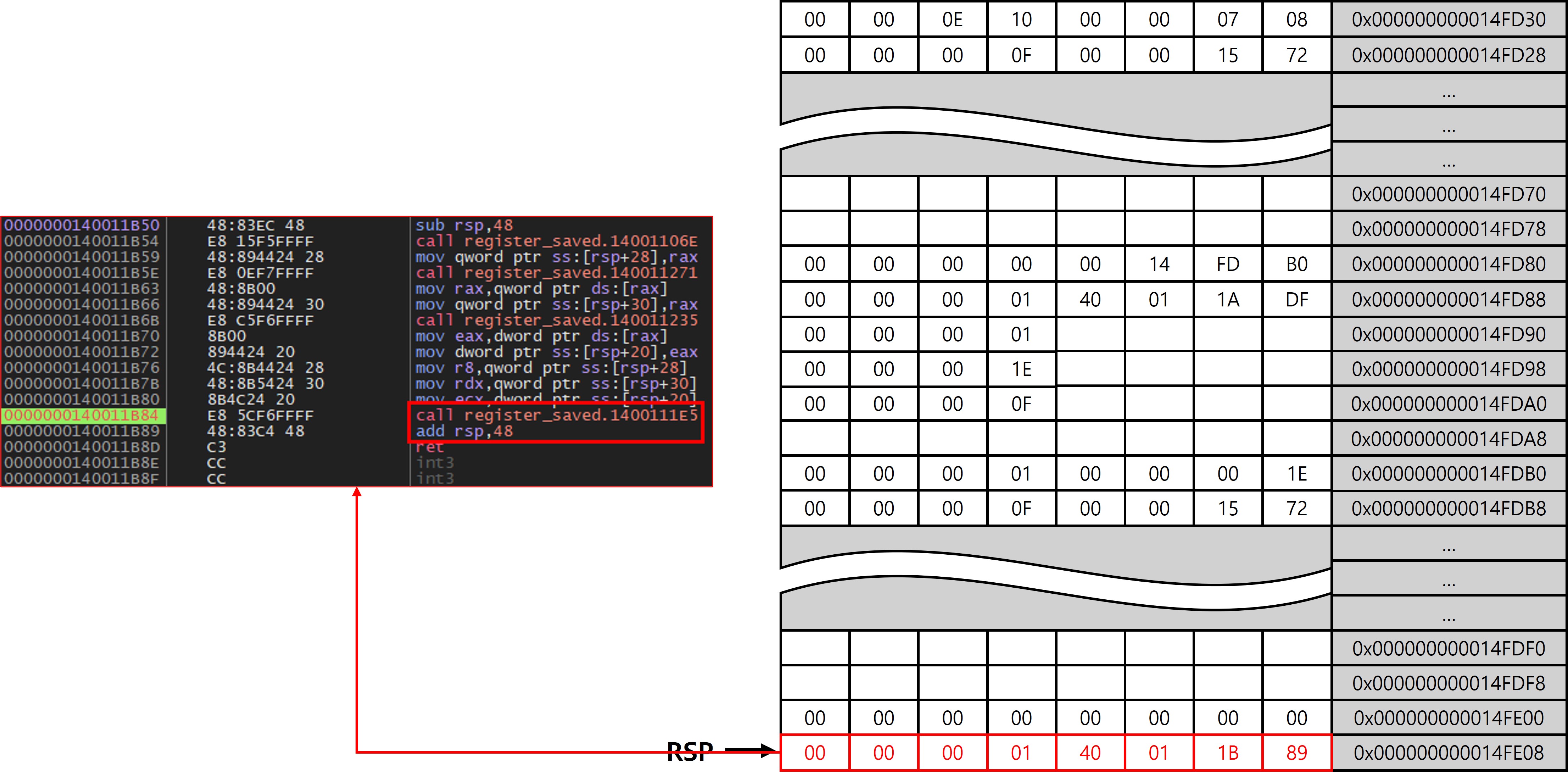
main 함수가 호출된 위치는 위와 같으며 main 함수 종료 후, 에필로그의 ret에서 pop eip를 통해 0x0000000140011B89의 코드가 실행된다.
3-3. 스택 프레임 분석 (Opt-Mid)
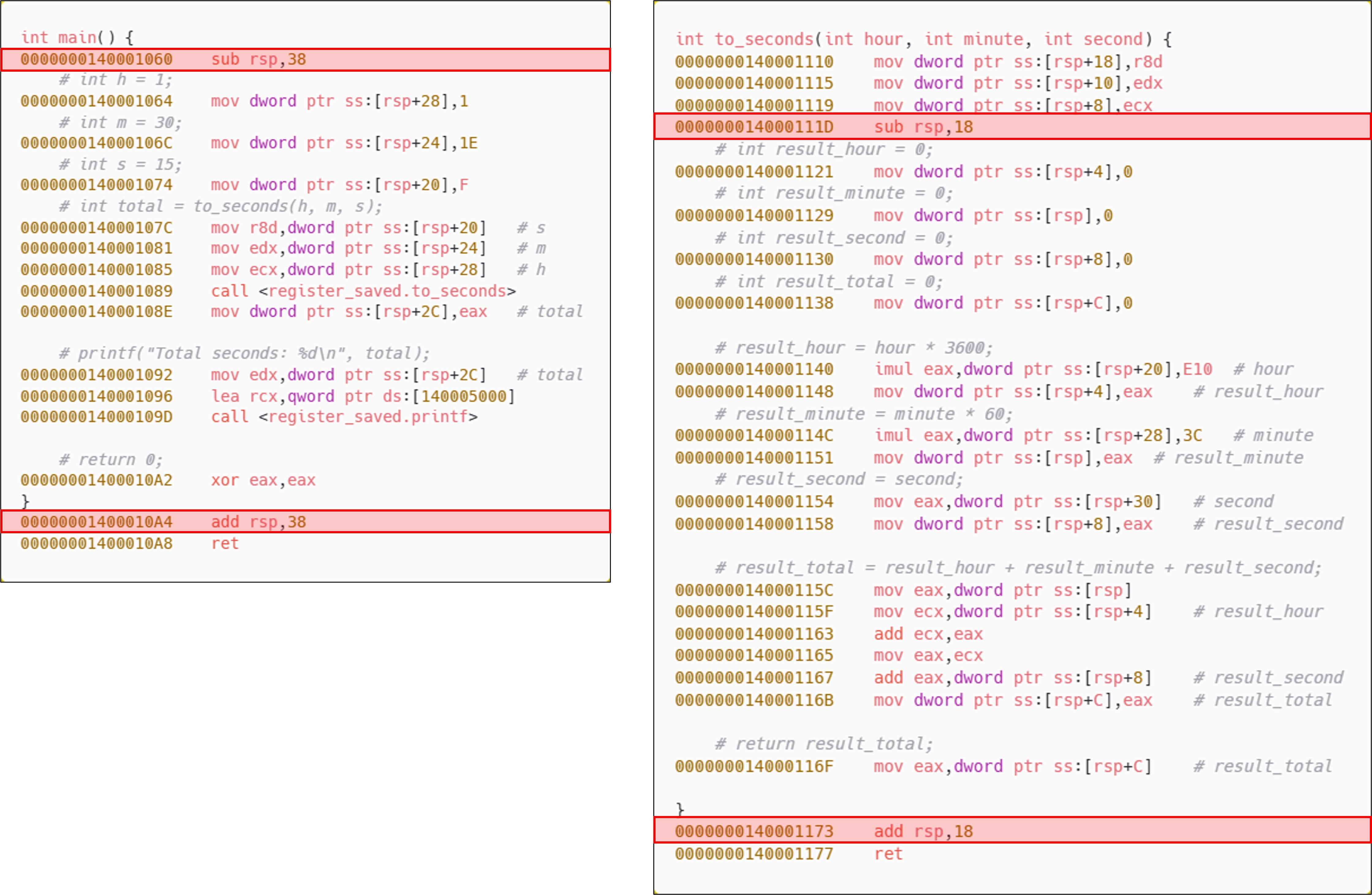
Opt-Mid로 나타나는 패턴을 확인해 보면 함수의 프롤로그에서 확보한 크기만큼 에필로그에서 스택을 정리하는 것을 확인할 수 있다. 또한 RBP를 사용하지 않기 때문에 SFP를 스택에 저장하는 동작을 하지 않는 것도 살펴볼 수 있다.

RBP를 사용하지 않기 때문에 함수의 body, prologue에서 인자, 로컬 변수를 참조할 때 RSP가 기준이 된다는 사실을 확인할 수 있다. 이때, RSP는 스택 포인터와 프레임 포인터 역할을 동시에 수행하게 된다.
4. 스택 프레임의 경계
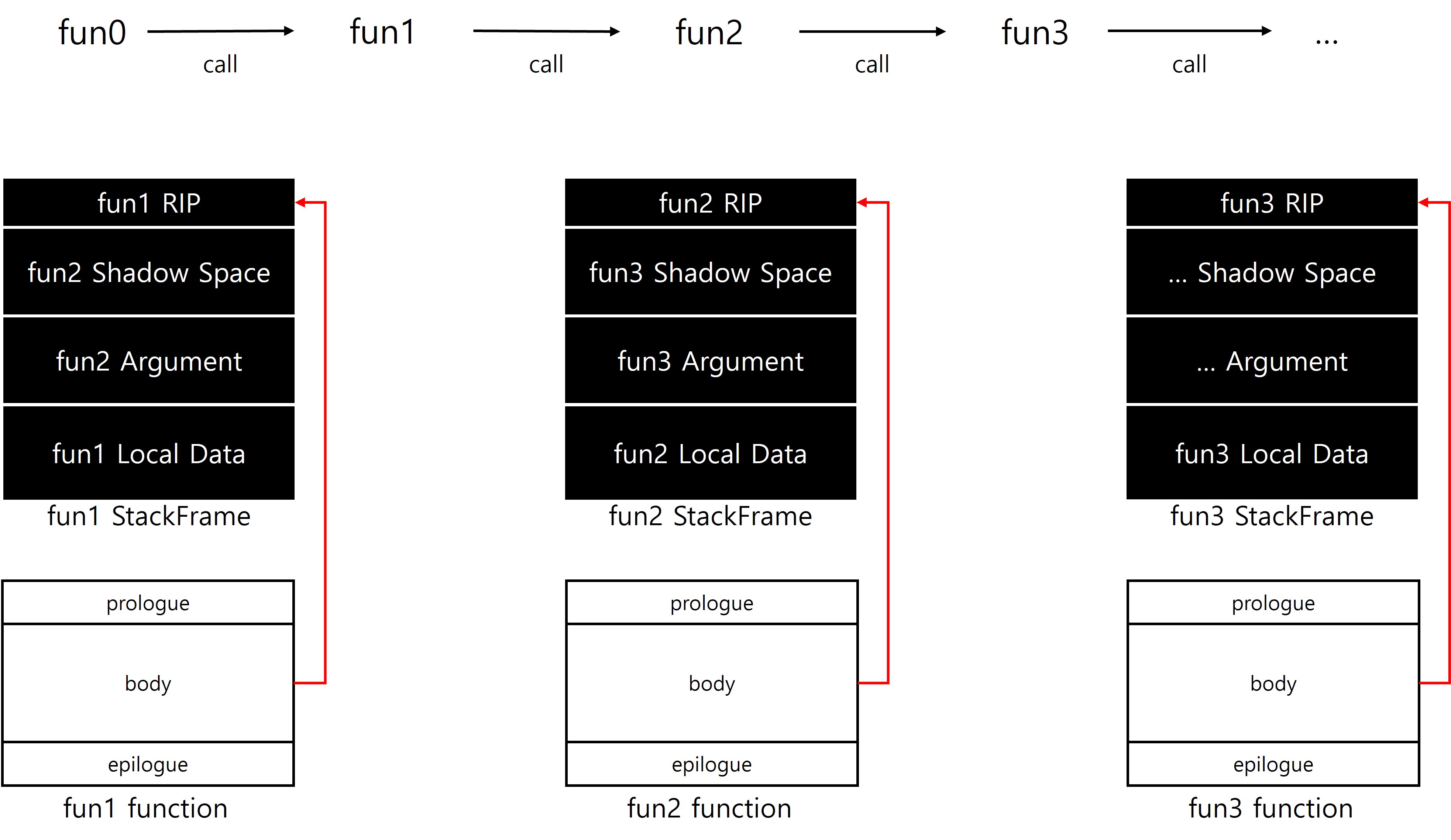
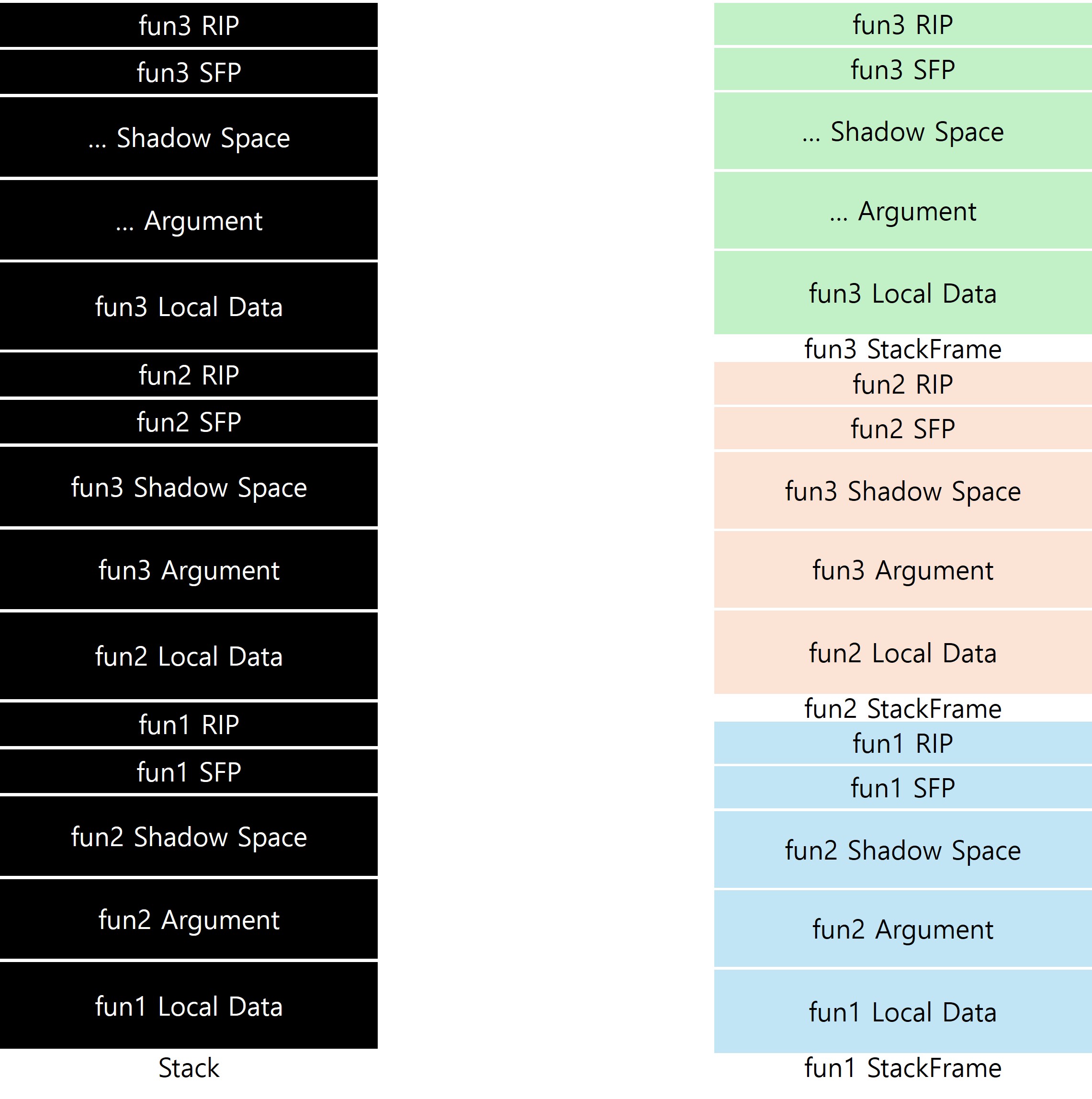
x64는 기능적, 구조적 배치가 어느정도 일치하는 스택 프레임을 형성하기 때문에, x32와 비교해 스택 프레임의 경계를 구분하기가 상대적으로 용이하다. 프레임 간 경계를 RIP(리턴 주소)를 기준으로 명확히 식별할 수 있는 구조적 장점을 갖는다.
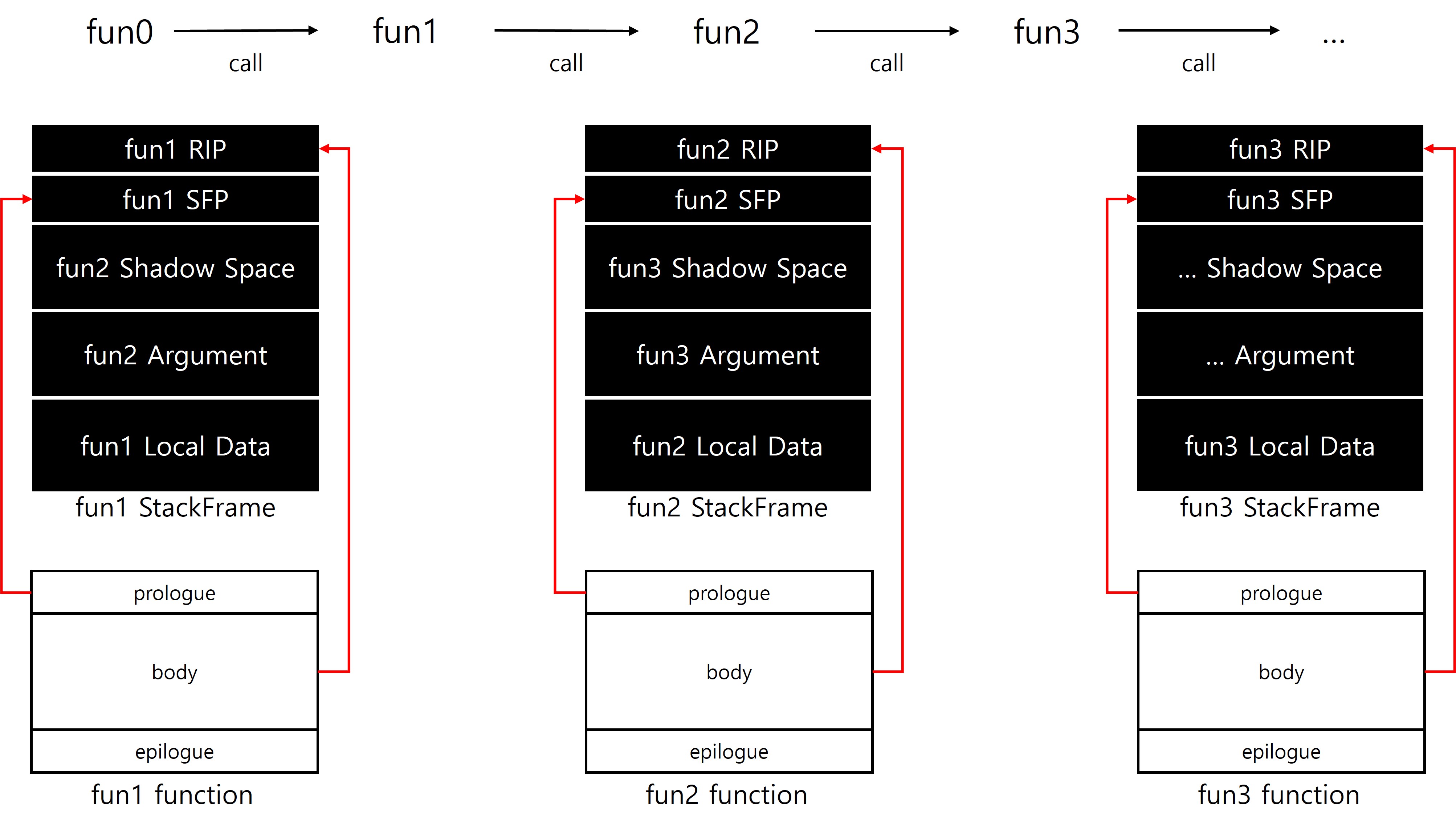
RBP를 활용하는 스택 프레임에서도 x64는 RIP(리턴 주소)를 기준으로 각 함수의 스택 프레임을 명확히 구분할 수 있다. 반면 x32에서는 EIP(리턴 주소)와 SFP(프레임 포인터)가 인자 영역과 로컬 데이터 영역 사이에 위치하고 있어, 단순한 구조 구분이 어려워 기능적, 구조적 기준을 따로 고려해야 했다. 하지만 x64에서는 push, pop 명령이 프롤로그와 에필로그에 한정되어 사용되고, 함수 body에서는 RSP의 16byte 정렬이 유지되도록 강제되기 때문에, 프롤로그에서 sub rsp, imm 명령으로 한 번에 전체 스택 프레임 영역을 확보하는 구조가 일반적이다. 이로 인해 각 함수는 이전 RIP부터 자신의 RIP에 이르기까지 하나의 독립된 스택 프레임으로 구분할 수 있다.
5. 참고 문헌
[1] x64 호출 규칙, https://learn.microsoft.com/ko-kr/cpp/build/x64-calling-convention?view=msvc-170
[2] x64 스택 사용, https://learn.microsoft.com/ko-kr/cpp/build/stack-usage?view=msvc-170
'Reversing > Definition' 카테고리의 다른 글
| [Definition] x32 ABI (0) | 2025.07.22 |
|---|---|
| [Definition] 64비트 함수 호출 규약 (64bit Calling Convention) (0) | 2025.07.19 |
| [Definition] 32비트 함수 호출 규약 (32bit Calling Convention) (5) | 2025.07.14 |
| [Definition] 32비트 스택 프레임 (32bit Stack Frame) (0) | 2025.07.13 |
| [Definition] 컴파일 (Compilation) (0) | 2025.07.10 |



