
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 코드엔진
- Programmers
- crackme
- 실행파일
- Python
- 함수 호출 규약
- __stdcall
- 크랙미
- 리치헤더
- ABI
- stack frame
- x64
- 파이썬
- Dos Stub
- Reversing
- Calling Convention
- 리버싱
- pe format
- x32
- image section header
- Rich Header
- rev
- __cdecl
- Image dos header
- CodeEngn
- 32bit
- __fastcall
- RVA
- __vectorcall
- 프로그래머스
- Today
- Total
kj0on
[Definition] x32 ABI 본문
1. 정의
ABI (Application Binary Interface)는 어플리케이션과 운영체제 또는 컴파일된 코드 간의 상호작용 방식을 정의한 이진 수준의 규약이다. 쉽게 말해, 컴파일된 바이너리들이 서로 호환되도록 하는 규칙 모음을 뜻한다.
2. x32 ABI
| 규칙 | 역할 | 필수 규칙(ABI) | 조건부 규칙 |
| 스택 정렬 규칙 | Alignment (정렬) |
모든 구간에서 ESP ≡ 0 (mod 4)를 유지해야 한다. | 16byte 정렬을 요구하는 SIMD 명령을 사용 할 경우, 함수 내부에서 추가 정렬을 보장해야 한다. |
| 레지스터 보존 규칙 | Register Save (레지스터 보존) |
Callee(피호출자)에서 비휘발성 레지스터를 사용했다면 함수 내부에서 원래 값으로 복구해야 한다. | 비휘발성 레지스터를 사용하지 않았다면 저장, 복구 코드가 없어도 된다. |
| 함수 호출 규약 | Parameter Passing (인자 전달) |
__stdcall, __cdecl, __fastcall, __vectorcall, ... | ... |
3. 스택 정렬 규칙
3-1. Hello World
3-1-1. 예제 코드
#include <stdio.h>
int main(void) {
printf("Hello World!\n");
getchar();
return 0;
}해당 프로그램은 실행 시 콘솔에 "Hello World!"라는 문자열을 출력하도록 작성된 코드이다.
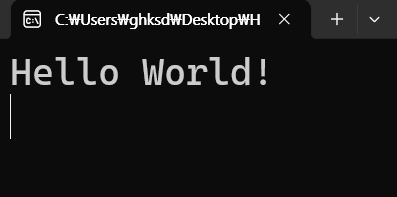
3-1-2. ESP 분석

32bit 환경에서는 기본 데이터 단위(word)가 4byte이므로 ESP는 항상 4의 배수로 정렬되어야 하며, 윈도우 로더와 링커는 프로그램 시작 시 ESP를 이미 4byte로 정렬된 상태로 설정한다. 이후 각 함수는 이 정렬을 유지한 채 인자 전달, 로컬 변수 할당, 함수 호출 등을 수행한다. 이렇게 정렬을 유지하면 메모리 접근 시 정렬 예외를 방지하고, 성능 이점을 얻을 수 있다. 결과적으로, x32에서는 스택 정렬이 구조적 안전성과 호환성을 보장하는 기본 규칙으로 기능한다.

함수 프롤로그에서 로컬 변수나 임시 데이터를 저장하기 위해 스택 공간을 확보할 때, 항상 4byte 정렬을 유지한 채 크기를 계산하고 할당하는 방식이 사용된다.
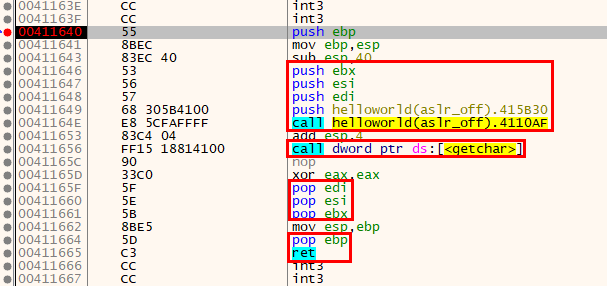
이후 함수 내부에서 사용하는 push, pop 명령어 또한 4byte 단위로 ESP를 증감시키기 때문에, 전체적인 스택 정렬이 지속적으로 4byte 단위로 유지되도록 설계되어 있다.
3-2. SIMD
3-2-1. 예제 코드
#include <stdio.h>
#include <emmintrin.h>
void simd_add(float out[4], const float a[4], const float b[4])
{
__m128 va = _mm_load_ps(a);
__m128 vb = _mm_load_ps(b);
__m128 vc = _mm_add_ps(va, vb);
_mm_store_ps(out, vc);
}
int main(void) {
float out[4] = { 0, };
float a[4] = { 0.1f, 0.2f, 0.3f, 0.4f };
float b[4] = { 0.5f, 0.6f, 0.7f, 0.8f };
printf("Hello World!\n");
simd_add(out, a, b);
for (int i = 0; i < sizeof(out) / sizeof(float); i++){
printf("%.1f ", out[i]);
}
printf("\n");
getchar();
return 0;
}
해당 프로그램은 실행 시 콘솔에 "Hello World!"라는 문자열을 출력 한 뒤, SIMD를 활용해 float 배열 a와 b의 각 요소를 병렬로 더한 결과를 out 배열에 저장하고 출력하는 프로그램이다.
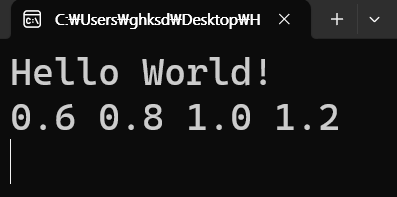
3-2-2. movaps
movaps reg, mem
movaps mem, reg
movaps reg, regmovaps 명령어는 x86/x64 아키텍처에서 사용되는 SSE (Streaming SIMD Extensions) 명령어 중 하나로, 16byte(128bit) 단위의 정렬된 데이터를 복사하는 명령어다.

메인 메모리에서 데이터를 읽을 때 16byte 정렬을 지키지 않으면 CPU의 캐시 서브시스템이 데이터를 효율적으로 로드하지 못하고 성능 저하가 발생할 수 있다. 이때 접근하려는 주소가 캐시 라인의 경계를 넘는 경우가 생기면 하나의 메모리 접근이 두 개의 캐시 라인에 걸쳐 처리된다. 이 과정에서 두 번의 메모리 접근과 바렐 시프터 또는 병합 로직을 통한 재조합 과정이 추가된다. 이러한 연산은 단순히 캐시 미스 발생 가능성을 높일 뿐 아니라 내부 마이크로아키텍처의 처리 경로까지 복잡하게 만들어 명령어 처리 속도를 감소시킨다.

movaps 명령은 16byte로 정렬된 메모리 주소에서만 동작하며, 정렬이 어긋난 상태에서 실행하면 EXCEPTION_ACCESS_VIOLATION 예외가 발생한다. 이는 CPU가 정렬 위반을 하드웨어 수준에서 막기 때문이며, 정렬되지 않은 주소에 안전하게 접근하려면 movups 명령을 사용해야 한다.
3-2-3. ESP 분석

16byte정렬은 4byte정렬을 보장하지만, 반대로 4byte정렬만으로는 16byte 정렬이 보장되지 않는다. x32ABI의 스택 정렬 규칙은 4byte정렬만 요구하기 때문에 16byte 정렬을 요구하는 SIMD 명령을 사용할 때는 함수 내부에서 별도로 재정렬이 필요하다.

이때 흔히 사용되는 방식 중 하나가 and esp, 0xFFFFFFF0 명령을 통해 하위 4bit를 0으로 마스킹하는 방식이다. 이 연산은 현재 ESP 값에서 16byte 정렬을 강제하며, 이후에 movaps를 사용할 때 정렬 위반 예외를 방지할 수 있다. 따라서 정렬을 요구하는 SSE 명령어를 사용하는 함수에서는 프롤로그에서 ESP 정렬을 보장하는 코드 패턴이 삽입되는 경우가 많다.

0xFFFFFFF0과 and 연산을 수행하면 하위 4bit가 0으로 변경되어 해당 값은 16byte 정렬 상태가 된다.

이는 이진수로 0xFFFFFFF0이 1111 1111 1111 1111 1111 1111 1111 0000이기 때문에, 어떤 값과 AND 연산을 하더라도 마지막 4bit는 강제로 0000이 되어 전체 값이 16byte로 정렬된다.

이러한 정렬 연산은 SIMD 명령 직전이 아닌 함수 프롤로그에서 나타날 수 있다. 함수 진입 시 컴파일러는 이후의 push, sub, add 연산까지 고려해 전체 스택 프레임이 최종적으로 16byte 정렬을 유지하도록 설계하며, 이를 통해 정렬 상태를 반복적으로 확인하거나 수정하지 않고도 SIMD 명령을 안전하게 사용할 수 있다.
4. 레지스터 보존 규칙
컴파일러는 ESI, EDI, EBX 및 EBP 레지스터가 함수에서 사용되는 경우 이러한 레지스터를 저장하고 복원하는 프롤로그 및 에필로그 코드를 생성합니다.
Microsoft의 문서에 따르면, ESI, EDI, EBX, EBP는 비휘발성(non-volatile) 레지스터로 간주하며, 함수 내에서 이들을 사용하는 경우 해당 함수는 이 레지스터들의 값을 호출 시점과 동일하게 유지해야 한다고 명시되어 있다.
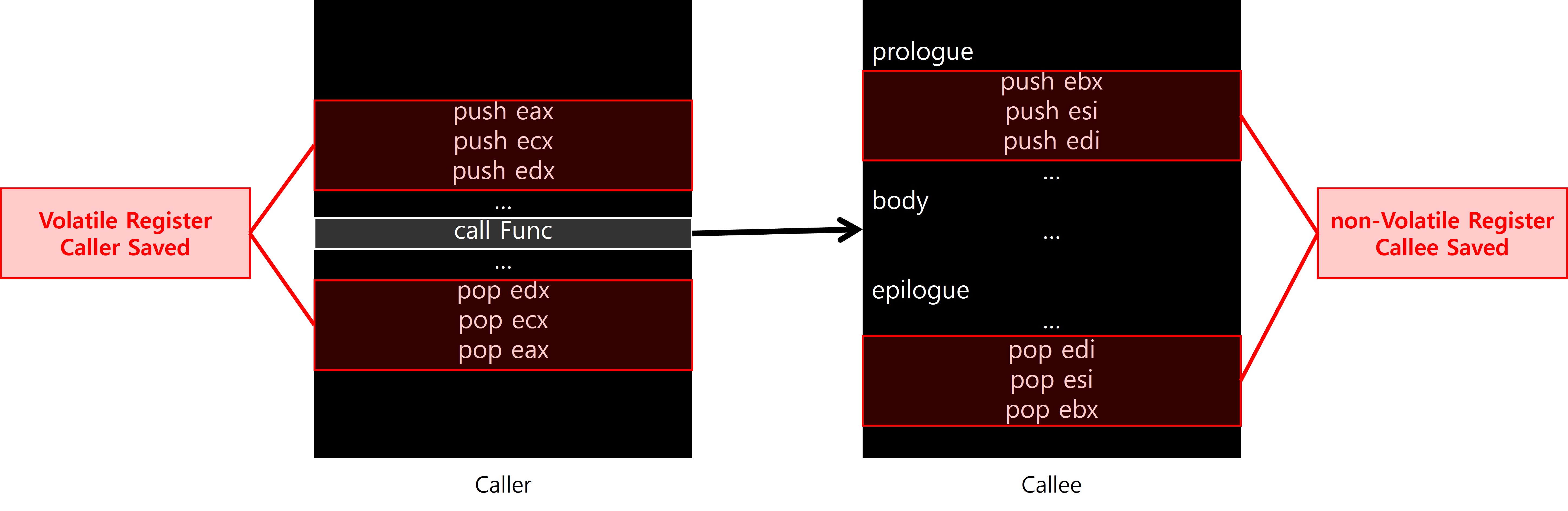
| 분류 | 보존 책임 | 의미 |
| 휘발성 레지스터 (Volatile) | Caller-Saved | 호출 직후 값이 보존된다고 기대할 수 없다. 필요하면 호출자가 따로 저장해야 한다. |
| 비휘발성 레지스터 (non-Volatile) | Callee-Saved | 호출 전, 후의 값이 같아야 한다. 피호출자가 해당 레지스터를 쓰면 반드시 원래 값으로 복구해야 한다. |
휘발성(volatile), 비휘발성(non-volatile)는 레지스터 자체의 물리적인(하드웨어) 특성이 아닌, Caller(호출자)의 시점에서 바라본 레지스터의 특성이다. Caller(호출자) 입장에서는 휘발성 레지스터는 Callee(피호출자)가 보존해 주지 않기 때문에 호출 시점에서 값이 변경(휘발성) 될 수 있다고 보는것이다. 반대로 비휘발성 레지스터는 Callee(피호출자)가 함수 내부에서 직접 보존하기 때문에 호출 시점에 값이 변경되지 않는(비휘발성)것으로 판단할 수 있다는 것이다.
| 구분 | 레지스터 |
| 휘발성 레지스터 |
EAX, ECX, EDX |
| 비휘발성 레지스터 |
ESI, EDI, EBX, EBP |
MS 공식 문서에서는 위와 같이 레지스터를 휘발성과 비휘발성으로 구분한다. 자주 덮어쓰는 값은 휘발성, 오래 보존할 값은 비휘발성으로 지정된다.
| 설계 목표 | 설명 |
| 호출자, 피호출자 간 비용 부담 분배 | 모든 레지스터를 항상 callee-saved(피호출자 보존)로 지정하면 모든 함수의 prologue와 epilogue에 push와 pop이 반복되어 코드 크기와 스택 사용량이 증가하는 문제가 생긴다. 반면, 모든 레지스터가 caller-saved(호출자 보존)로 지정되면 호출이 발생할 때마다 호출자가 직접 레지스터 값을 보존해야 해서 호출 빈도가 높을수록 오버헤드가 커진다. 따라서 ABI는 호출자와 피호출자가 모두 보존하도록 비용을 나눠 균형있게 분담하도록 한다. |
| 데이터 수명에 따른 역할 분담 | 데이터의 생명주기(lifetime)를 기준으로, 루프 인덱스나 베이스 포인터와 같은 장기간 살아 있는 값은 비휘발성 레지스터에, 반대로 임시적이고 짧은 계산에 사용되는 값은 휘발성 레지스터에 할당 하고 있다. 호출자는 장기 데이터를 안전하게 유지하면서도, 단기적인 계산에서는 부담 없이 레지스터를 자유롭게 사용할 수 있다. |
| 컴파일러 최적화 | 컴파일러가 레지스터 할당할 때 함수 내 호출 빈도에 따라 휘발성 레지스터, 비휘발성 레지스터의 비용(weight)을 다르게 설정하는 휴리스틱을 적용해 최적화를 수행한다. 이 구분을 활용하여 불필요한 메모리 접근 횟수를 감소시킬 수 있다. |
| 다양한 언어 및 모듈 간 호환성 | 저장 및 복원의 책임이 모듈마다 다르다면 링크는 가능할지 몰라도 실행 과정에서 상태가 훼손되어 제대로 동작하지 않을 위험이 있다. |
비휘발성 및 휘발성 레지스터 구분은 호출자와 피호출자간의 효율적인 역할 분담과 비용 최소화를 위해 필수적이다. 모든 레지스터를 동일하게 취급하여 보존 여부를 상황에 따라 결정하면 각 함수를 호출될 때마다 추가적인 분석과 판단이 요구되어 컴파일러 및 런타임 오버헤드가 발생할 수 있다. 또한, 이 경우 호출자와 피호출자 간의 보존 규약이 명확하지 않아 서로 다른 모듈이나 언어 간 상호작용 시 예기치 않은 상태 변경으로 인한 오류 위험이 증가한다. 반면, ABI에서 레지스터를 미리 휘발성과 비휘발성으로 명확히 구분하면 호출 시점마다 보존 여부를 판단할 필요가 없어지고, 각 함수는 이 규약을 신뢰하여 독립적으로 최적화된 코드를 생성할 수 있다. 결과적으로 이러한 명확한 구분은 코드의 안정성 및 유지보수성을 높이고, 다양한 언어나 모듈 간의 원활한 연동과 함께 컴파일러의 최적화 효율을 극대화하는 데 기여한다.
5. 함수 호출 규약
x32 함수 호출 규약에 대한 자세한 내용은 https://kj0on.tistory.com/42 참고
6. 참고 문헌
[1] 인수 전달 및 명명 규칙, https://learn.microsoft.com/ko-kr/cpp/cpp/argument-passing-and-naming-conventions?view=msvc-170
[2] x86 calling conventions, https://en.wikipedia.org/wiki/X86_calling_conventions
'Reversing > Definition' 카테고리의 다른 글
| [Definition] 라이브러리 (Library) (0) | 2025.07.24 |
|---|---|
| [Definition] x64 ABI (2) | 2025.07.22 |
| [Definition] 64비트 함수 호출 규약 (64bit Calling Convention) (0) | 2025.07.19 |
| [Definition] 64비트 스택 프레임 (64bit Stack Frame) (0) | 2025.07.15 |
| [Definition] 32비트 함수 호출 규약 (32bit Calling Convention) (5) | 2025.07.14 |



