
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- stack frame
- x32
- Calling Convention
- __cdecl
- 리치헤더
- rev
- Python
- pe format
- Rich Header
- __vectorcall
- RVA
- Programmers
- 크랙미
- 프로그래머스
- 함수 호출 규약
- 리버싱
- crackme
- x64
- ABI
- __fastcall
- 파이썬
- __stdcall
- 실행파일
- Image dos header
- Dos Stub
- 32bit
- Reversing
- 코드엔진
- image section header
- CodeEngn
- Today
- Total
kj0on
[Definition] 64비트 함수 호출 규약 (64bit Calling Convention) 본문
0. 64비트 스택 프레임 (64bit Stack Frame)
64비트 스택프레임에 대한 자세한 설명은 https://kj0on.tistory.com/43 참고
1. 정의
함수와 호출자 간에 인수를 전달하고 값을 반환하기 위한 규칙
프로시저(함수) 호출 시 인자를 어디에 어떤 순서로 전달하고, 누가 스택을 정리하며, 레지스터를 보존할지, 어느 레지스터로 값을 반환할지 등을 규정한 저수준 인터페이스 계약이다. 컴파일러, 언어, OS, CPU가 서로 다른 오브젝트 코드를 같은 ABI 안에서 링크 및 호출할 수 있게 해준다.
2. Caller(호출자)와 Callee(피호출자)
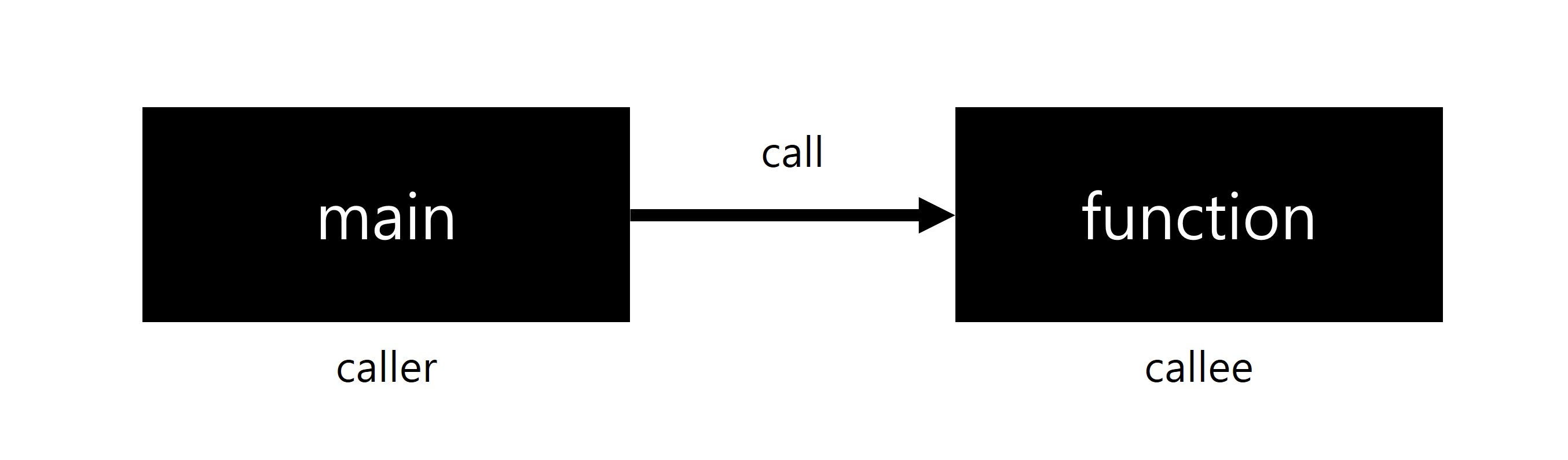
Caller는 함수를 호출하는 쪽이고, Callee는 호출된 함수이다. Caller는 인자를 준비하고 제어를 Callee에게 넘기며, Callee는 이를 받아 작업을 수행한 뒤 결과를 반환한다. 이 과정에서 책임이 명확하게 나뉘며, 어떤 쪽이 어떤 책임을 지는지는 사용된 호출 규약에 따라 사전에 정해진 방식으로 결정된다.
3. 함수 호출 규약 분류

Win16 및 초기 컴파일러 환경에서는 각 프로그래밍 언어마다 고유한 호출 방식이 존재했고, 운영체제 내부용 전용 호출 규약도 함께 사용되었다. 그러나 이러한 다양성은 호환성 문제와 확장성의 한계를 드러냈고, 결국 Win32 시대에 들어 실무적으로 표준화된 호출 규약들이 등장하면서 언어나 환경을 넘어 보다 효율적이고 일관된 방식으로 정립되기 시작했다. 이후 Win64 환경에서는 아예 단일 호출 규약이 강제되어 모든 언어와 컴파일러가 통일된 방식으로 함수를 호출하게 되었으며, 사실상 호출 규약 간의 차이가 사라졌다.
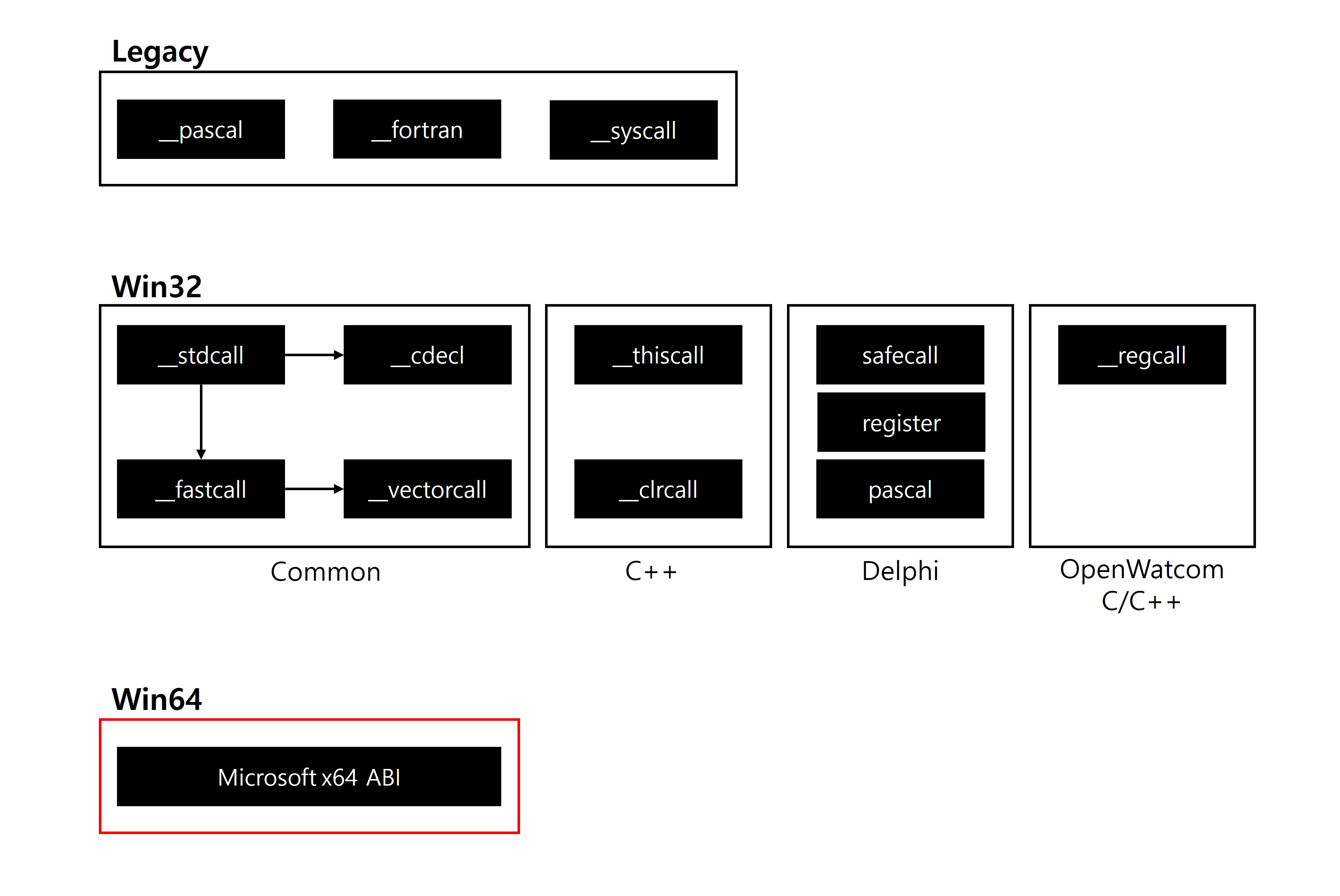
이 글에서는 x64 ABI 만 집중적으로 다룬다.
4. Windows x64 함수 호출 규약
Windows x32에는 __cdecl, __stdcall, __fastcall, __vectorcall 등 다수의 호출규약이 공존했으나, x64로의 전환 과정에서 플랫폼별로 하나의 표준 호출규약만 남도록 설계가 단순화되었다. Windows x64 calling convention이라는 단일 규격을 강제함으로써 모듈이 모두 동일한 규칙을 공유한다. 이러한 통일은 레지스터 전달로 인한 성능 이점과 시스템 수준 최적화를 가능케 하며, 하나의 규약만 알면 모든 바이너리가 호환된다는 이점을 얻게 되었다.
4-1. 예제 코드
#include <stdio.h>
int int_add_fun(int a, int b, int c, int d, int e, int f) {
int i1 = a;
int i2 = b;
int i3 = c;
int i4 = d;
int i5 = e;
int i6 = f;
int result = 0;
result = i1 + i2 + i3 + i4 + i5 + i6;
return result;
}
float float_add_fun(float a, float b, float c, float d, float e, float f) {
float f1 = a;
float f2 = b;
float f3 = c;
float f4 = d;
float f5 = e;
float f6 = f;
float result = 0;
result = f1 + f2 + f3 + f4 + f5 + f6;
return result;
}
int main() {
int int_result = int_add_fun(1, 2, 3, 4, 5, 6);
printf("%d + %d + %d + %d + %d + %d = %d\n", 1, 2, 3, 4, 5, 6, int_result);
float float_result = float_add_fun(0.1f, 0.2f, 0.3f, 0.4f, 0.5f, 0.6f);
printf("%.1f + %.1f + %.1f + %.1f + %.1f + %.1f = %.1f\n", 0.1f, 0.2f, 0.3f, 0.4f, 0.5f, 0.6f, float_result);
return 0;
}이 코드는 6개의 정수를 더하는 함수 int_add_fun과 6개의 소수를 더하는 함수 float_add_fun을 정의하고, 이를 main 함수에서 호출하여 결과를 출력하는 간단한 예제이다.

4-2. Windows x64 calling convention

| 항목 | 설명 | |
| 레지스터 (Register) | 스택 (Stack) | |
| 인수 전달 순서 | 왼쪽 → 오른쪽 (Left to right) | 오른쪽 → 왼쪽 (Right to left) |
| 인수 전달 매체 | RAX, RDX, R8, R9 XMM0 ~ XMM3 |
Stack |
| 스택 유지 관리 책임 | X | 호출자 (Caller) |
| 함수 이름 데코레이션 | <function name> | |
4-2-1. 인수 전달 순서

인수는 데이터 종류에 따라 정수용 및 포인터용 레지스터와 부동소수점용 레지스터로 분리되어 전달된다. 정수형 및 포인터형 인수는 왼쪽에서 오른쪽 순서로 RCX → RDX → R8 → R9 레지스터에 순차적으로 할당되며, 다섯 번째 이후의 인수는 오른쪽에서 왼쪽 순서로 스택에 저장된다. 부동소수점 및 SIMD 인수는 왼쪽에서 오른쪽 순서로 XMM0 ~ XMM3까지 사용된다. 이 경우에도 초과 인수는 오른쪽에서 왼쪽으로 스택에 저장된다. 이때 스택에 저장되는 인수는 모두 Shadow Space를 피해서 저장해야 한다. 구조체, 64비트 이상 정수, 16바이트 이상의 벡터 타입 등은 종류에 따라 레지스터 분할 전달, 포인터 전달, 메모리 복사 후 포인터 전달 방식으로 전달되며, 대부분의 경우 RCX~R9 또는 스택에 포인터 형태로 전달된다.
4-2-2. 인수 전달 매체
x64 ABI에 따르면 Caller(호출자)는 함수 호출 시 항상 32byte의 Shadow Space를 스택에 미리 확보해야 하며, Callee(피호출자)는 이 공간을 자유롭게 활용할 수 있다. 이 공간은 주로 원래의 인자 값을 보존하기 위해 사용한다. 또한 디버그 빌드에서는 모든 인자를 추적 가능하도록 하기 위해, Callee(피호출자)는 함수 프롤로그에서 Shadow Space 영역에 레지스터 값을 항상 스택에 저장하는 방식으로 코드를 생성한다. 위는 디버그 빌드에 의해 나타난 결과다.
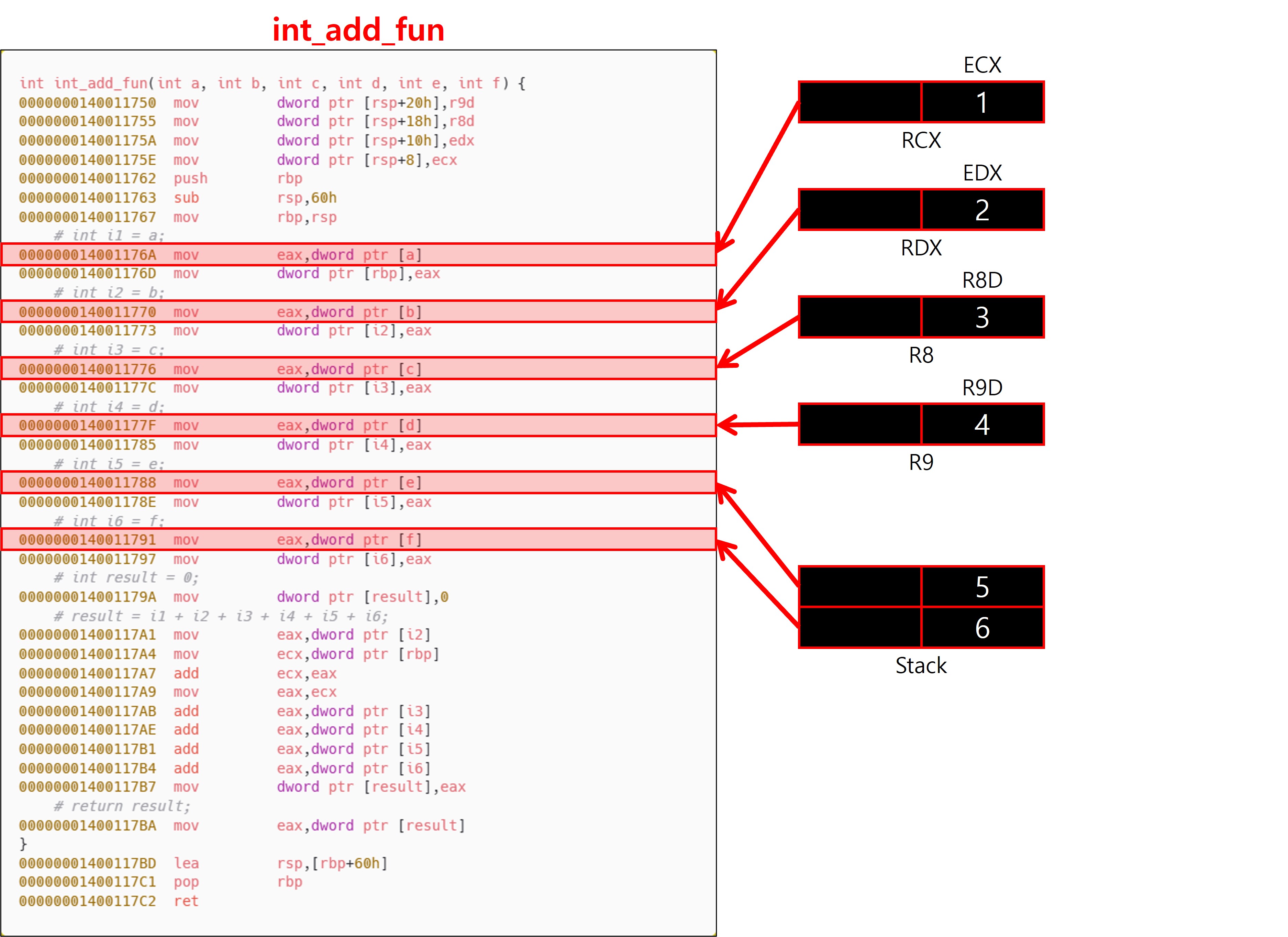
정수형 및 포인터형 인수는 RCX, RDX, R8, R9 레지스터를 사용하며, 이 네 개를 초과하는 인수는 스택을 통해 전달된다.
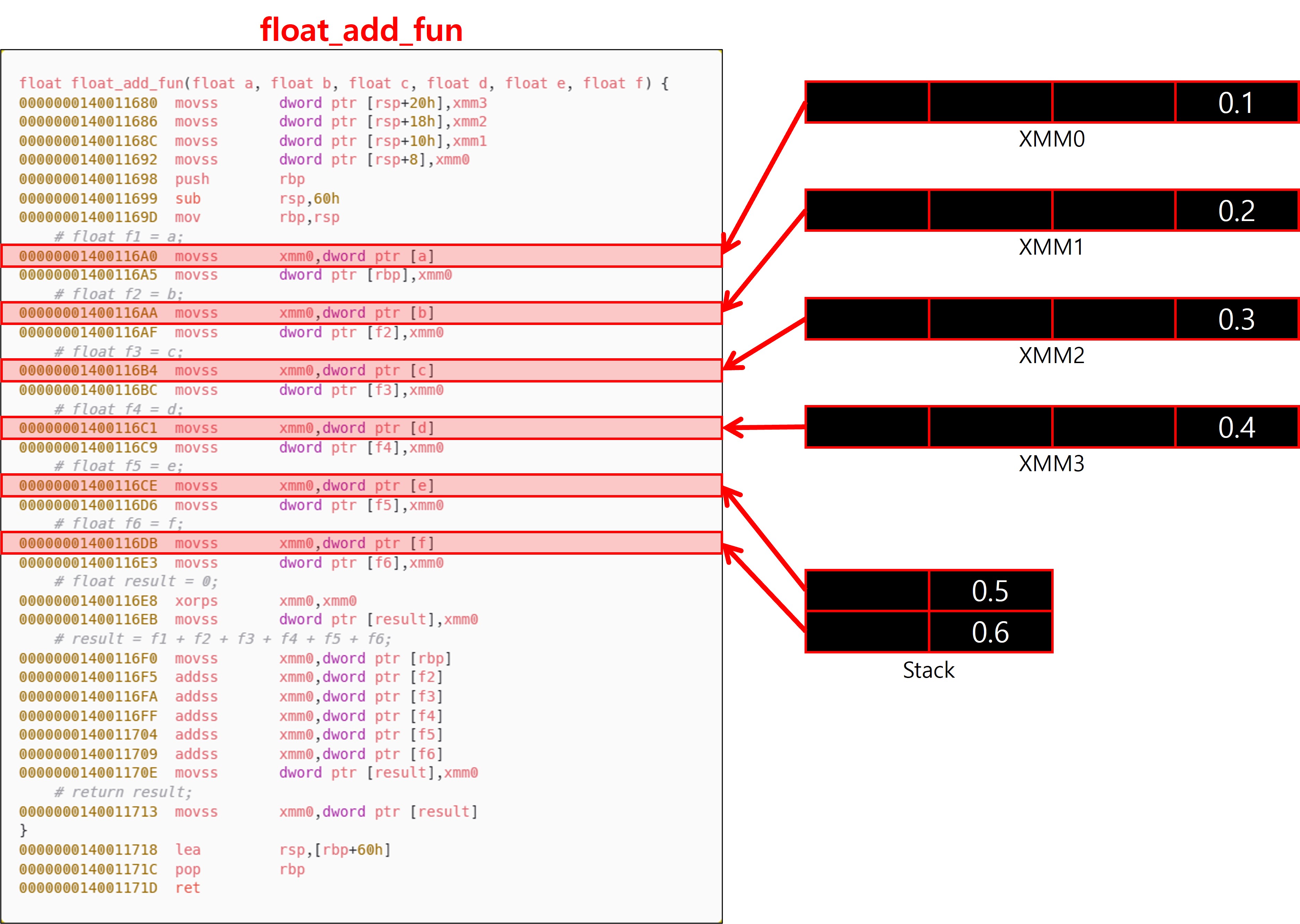
부동소수점 및 SIMD 인수는 XMM0, XMM1, XMM2, XMM3까지 최대 4개 레지스터를 사용하며, 이 네 개를 초과하는 인수는 스택을 통해 전달된다.
4-2-3. 스택 유지 관리 책임
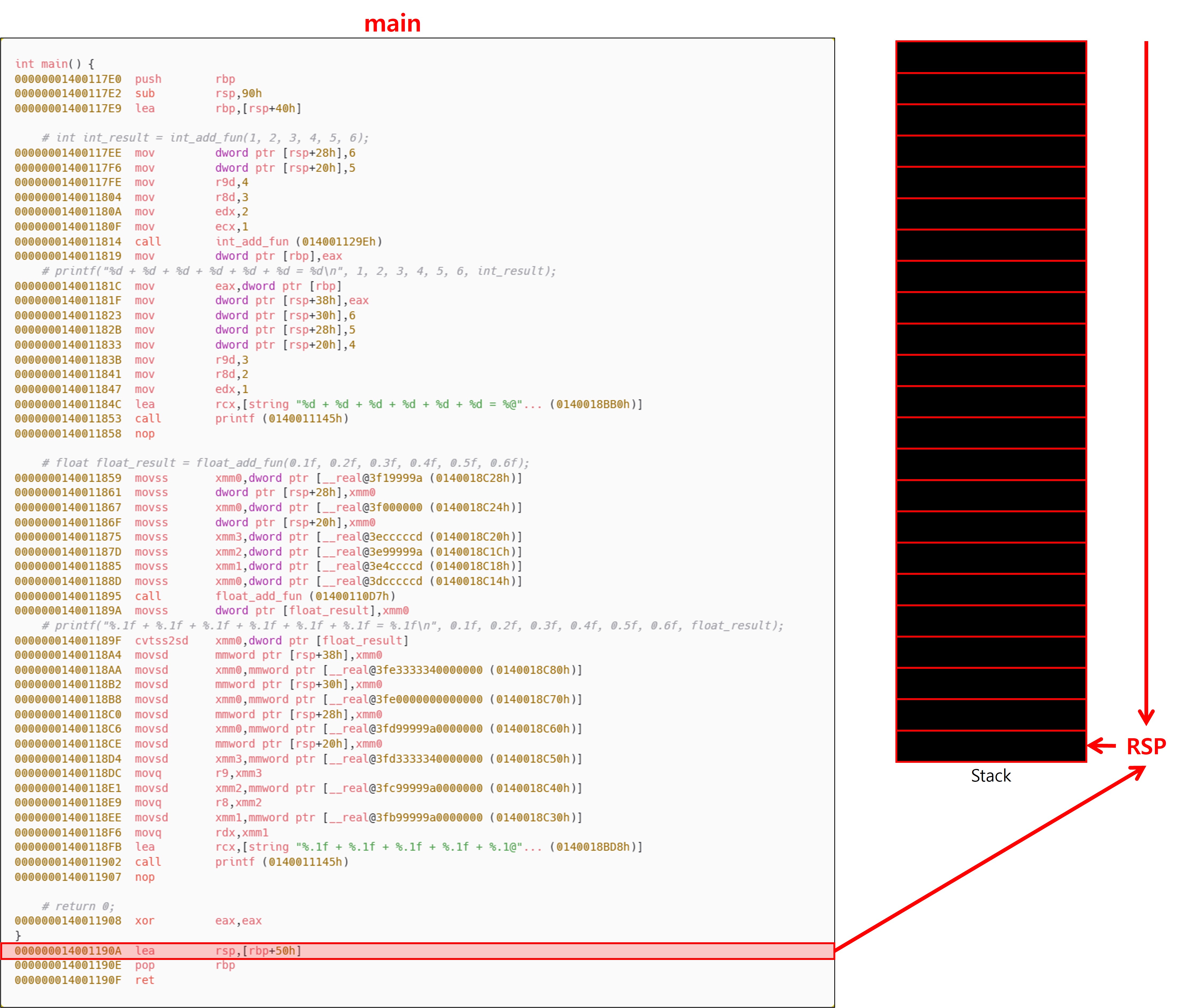
스택 유지 관리 책임은 Caller(호출자)에게 있으며, 함수 호출 전후에 RSP 값을 원래 상태로 되돌리는 작업은 호출자가 수행해야 한다.
4-2-4. 함수 이름 데코레이션

함수 이름 데코레이션은 적용되지 않는다. 함수 이름은 소스 코드와 동일한 이름 그대로 기록되며, 접두사나 접미사가 붙지 않는다.
5. Caller cleans the stack (Caller-pop / Caller-cleans)

Callee(피호출자)의 에필로그에서 add 또는 leave 명령과 같이 스택 포인터를 복원하는 코드를 확인할 수 있는데, 이는 마치 Callee가 콜스택을 정리하는 것처럼 보일 수 있다. 그러나 이러한 동작은 전적으로 Callee 내부에서 사용한 스택 프레임에 대한 정리에 불과하다. 이는 해당 명령어가 어디까지 스택을 정리하는지를 확인해 보면 쉽게 알 수 있다.

인자가 총 6개이기 때문에 4개의 인자(1, 2, 3 , 4)는 레지스터(RCX, RDX, R8, R8)로 전달되고, 나머지 2개의 인자(5, 6)은 스택으로 전달된다. 이때, Shadow Space 또한 Caller에서 할당하기 때문에 이 공간을 피해서 스택에 저장된다. 값을 확인해 보면 int_add_fun 함수를 호출하기 전, 스택의 상태는 위와 같다.

int_add_fun의 에필로그에 나타나는 lea rsp, [rbp+60h] 또는 add rsp, imm 명령을 실행한 결과, 이는 int_add_fun 함수 내부에서 확보했던 Local 영역만 정리하고 호출자가 전달한 인자 영역은 그대로 남아 있다는 점을 통해, 해당 명령이 정리하는 범위가 피호출자 내부의 스택 프레임에 국한된다는 사실을 확인할 수 있다.

x32와 비교하면 x64 환경의 Callee(피호출자)의 에필로그에서 나타나는 스택 정리 명령은 x32에서의 mov esp, ebp 명령과 기능적으로 동일한 역할을 수행한다. 두 명령 모두 함수 진입 시 생성한 스택 프레임을 반환 직전에 원래 상태로 복구하는 용도로 사용되며, 로컬 변수 등 피호출자 내부에서 사용한 스택 영역만을 정리한다는 공통점을 가진다.
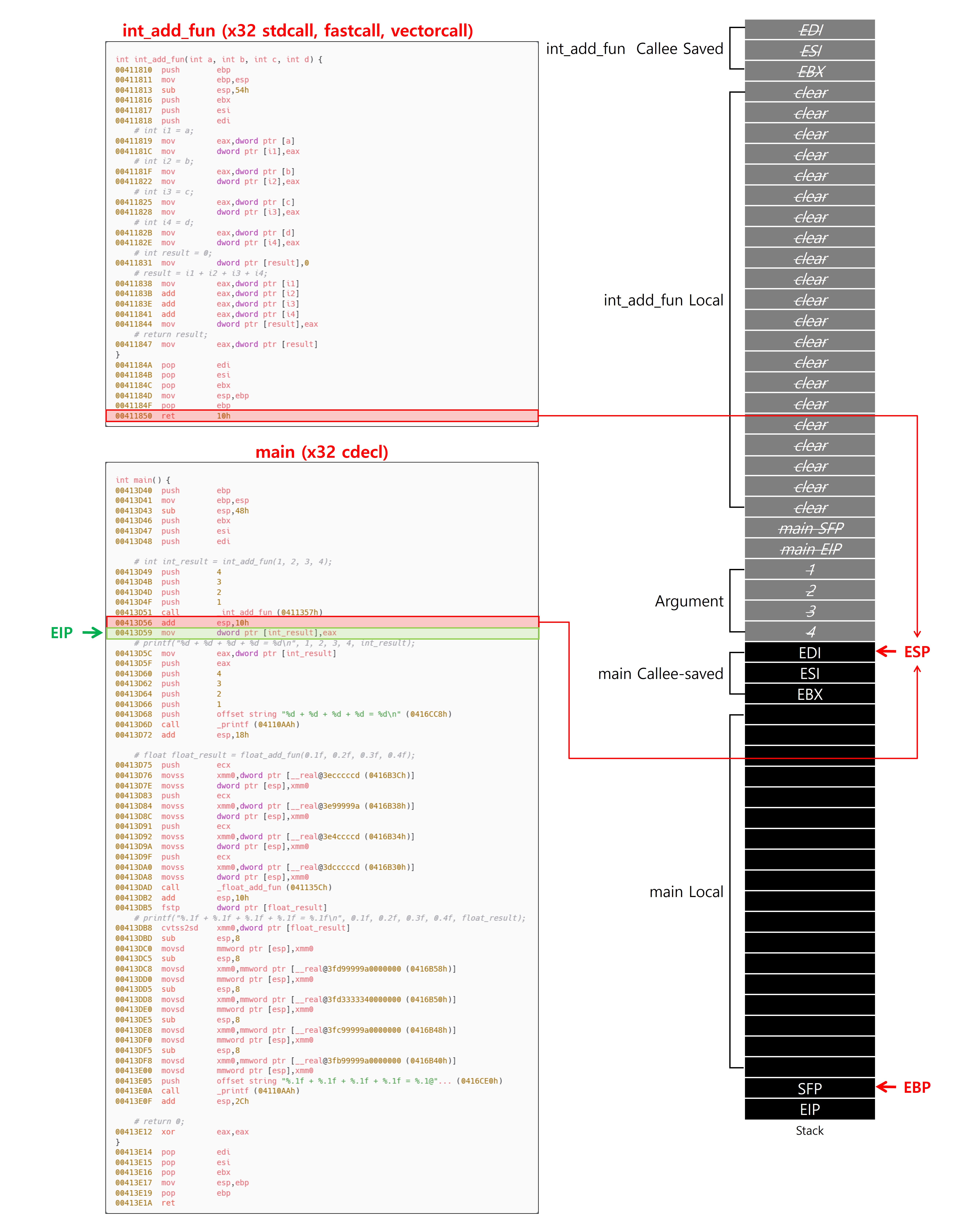
x32에서 실제로 스택이 정리되는 동작은 mov esp, ebp 이후에 나타난다. Callee에서 스택을 정리하는 경우(stdcall, fastcall, vectorcall) ret <n>으로 스택을 정리하고, Caller에서 스택을 정리하는 경우(cdecl) add esp, imm으로 스택을 정리한다. 따라서 스택을 정리한다는 것은 단순한 로컬 프레임 복원 뿐 아니라, 함수 호출에 사용된 인자 영역까지 포함한 전체 호출 컨텍스트의 정리를 의미한다.

x64에서 함수를 호출할 때 사용했던 Shadow Space와 Argument의 영역의 정리는 로컬 영역과 인자 영역을 포함한 전체 호출 컨텍스트의 정리를 의미한다. x32에서는 보통 Callee(피호출자)의 에필로그, 함수 호출 이후 Caller(호출자)의 바디에서 이루어진다. 반면, x64에서는 x32와는 다르게 Caller(호출자)의 에필로그에서 스택을 정리한다. 여기서 한가지 이상한 점이 있는데 Caller(호출자)의 에필로그에서 스택을 정리하는 동작은 모든 Caller(호출자) 함수에 존재한다는 것이다. 이 동작은 x32에서 __stdcall, __fastcall, __vectorcall 함수 호출 규약 역시 포함하고 있다. 그렇다면 모든 함수의 스택 정리 책임은 무조건 Caller(호출자)에 있는 것일까?

스택 정리 책임을 구분할 때는 로컬 영역과 인자 영역이라는 두 가지 서로 다른 영역을 구분해야 한다. 로컬 영역은 함수 내부에서 생성된 임시 데이터나 지역 변수를 저장하기 위한 공간으로, 언제나 해당 함수인 Callee(피호출자)가 진입 시 확보하고 반환 시 정리한다. 따라서 실행 환경과 호출 규약에 관계없이 로컬 영역은 언제나 Callee의 프롤로그에서 할당되고 에필로그에서 정리되는 것이 정해진 규칙이다.

스택 정리 책임이 어디에 있는지를 구분 할 때, 그 대상은 로컬 영역이 아니라 인자 영역에 한정된다. 함수 내부에서 사용되는 로컬 영역은 항상 Callee(피호출자)가 진입 시 할당하고 반환 시 정리하는 것으로 규약상 고정되어 있다. 여기에서는 스택 정리 책임을 구분 할 필요가 없다. 반면, 인자 영역에서는 가변 인자를 고려해 Caller(호출자)와 Callee(피호출자) 중 어디서 스택을 정리하는지를 구분해야 한다. 이 영역은 호출 규약에 따라 어느 쪽이 정리할지가 결정된다. 따라서 스택 정리 책임이라는 표현은 오직 인자 영역을 대상으로 한 개념이다.
| 함수 호출 규약 | 로컬 영역 | 스택 정리 책임 (인자 영역) | 위치 |
| __stdcall (x32) | Callee(피호출자) | Callee (피호출자) | Callee Epilogue |
| __cdecl (x32) | Callee(피호출자) | Caller (호출자) | Caller Body |
| __fastcall (x32) | Callee(피호출자) | Callee (피호출자) | Callee Epilogue |
| __vectorcall (x32) | Callee(피호출자) | Callee (피호출자) | Callee Epilogue |
| x64 calling convention (x64) | Callee(피호출자) | Caller (호출자) | Caller Epilogue |
따라서 "모든 함수의 스택 정리 책임은 무조건 Caller(호출자)에 있는 것일까?"라는 질문에 대한 답은 "x32에서 그렇지 않다."는 것이다. x32의 __stdcall, __fastcall, __vectorcall에서는 인자 영역이 Callee(피호출자)에 의해 정리되므로 스택 정리 책임은 Callee(피호출자)에게 있다(__cdecl은 호출자). 그렇기 때문에 스택 정리 책임이 무조건 Caller(호출자)에게 있다고 할 수 없다. 반면 x64에서는 호출 규약이 하나로 통일되었기 때문에 인자 영역 정리는 항상 Caller(호출자)의 책임으로 고정되어 있다. 그렇기 때문에 스택 정리 책임이 일관되게 Caller(호출자)에 있다고 할 수 있다.
6. 가변인자 (Variadic Arguments)
6-1. 예제 코드
#include <stdio.h>
#include <stdarg.h>
int main(void)
{
int total1 = var_add_fun(10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
int total2 = var_add_fun(3, 1, 2, 3);
int total3 = var_add_fun(3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20);
int total4 = var_add_fun(1000);
printf("total1 = %d\ntotal2 = %d\ntotal3 = %d\ntotal4 = %d\n", total1, total2, total3, total4);
return 0;
}
int var_add_fun(int count, ...)
{
int result = 0;
va_list args;
va_start(args, count);
for (int i = 0; i < count; ++i) {
result += va_arg(args, int);
}
va_end(args);
return result;
}위 코드는 가변 인자 n개를 모두 더한 뒤 그 합계를 printf로 출력하고 종료하는 프로그램이다.

| 변수 | count (덧셈 인자의 수) | 덧셈 | 결과 |
| total1 | 10 | 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 | 55 |
| total2 | 3 | 1 + 2 + 3 | 6 |
| total3 | 3 | 1 + 2 + 3 | 6 |
| total4 | 1000 | trash_value + ... + trash_value | -1641958797 |
6-2. 어셈블리 코드
6-2-1. main

6-2-2. var_add_fun
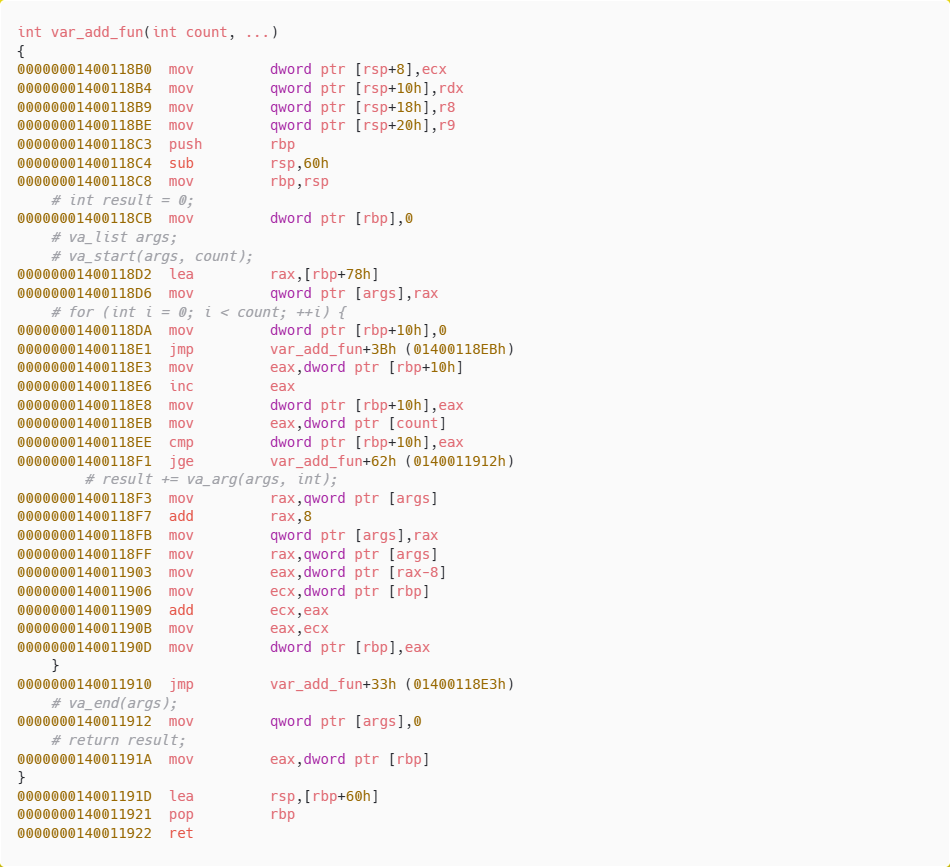
6-3. x64의 가변인자 처리
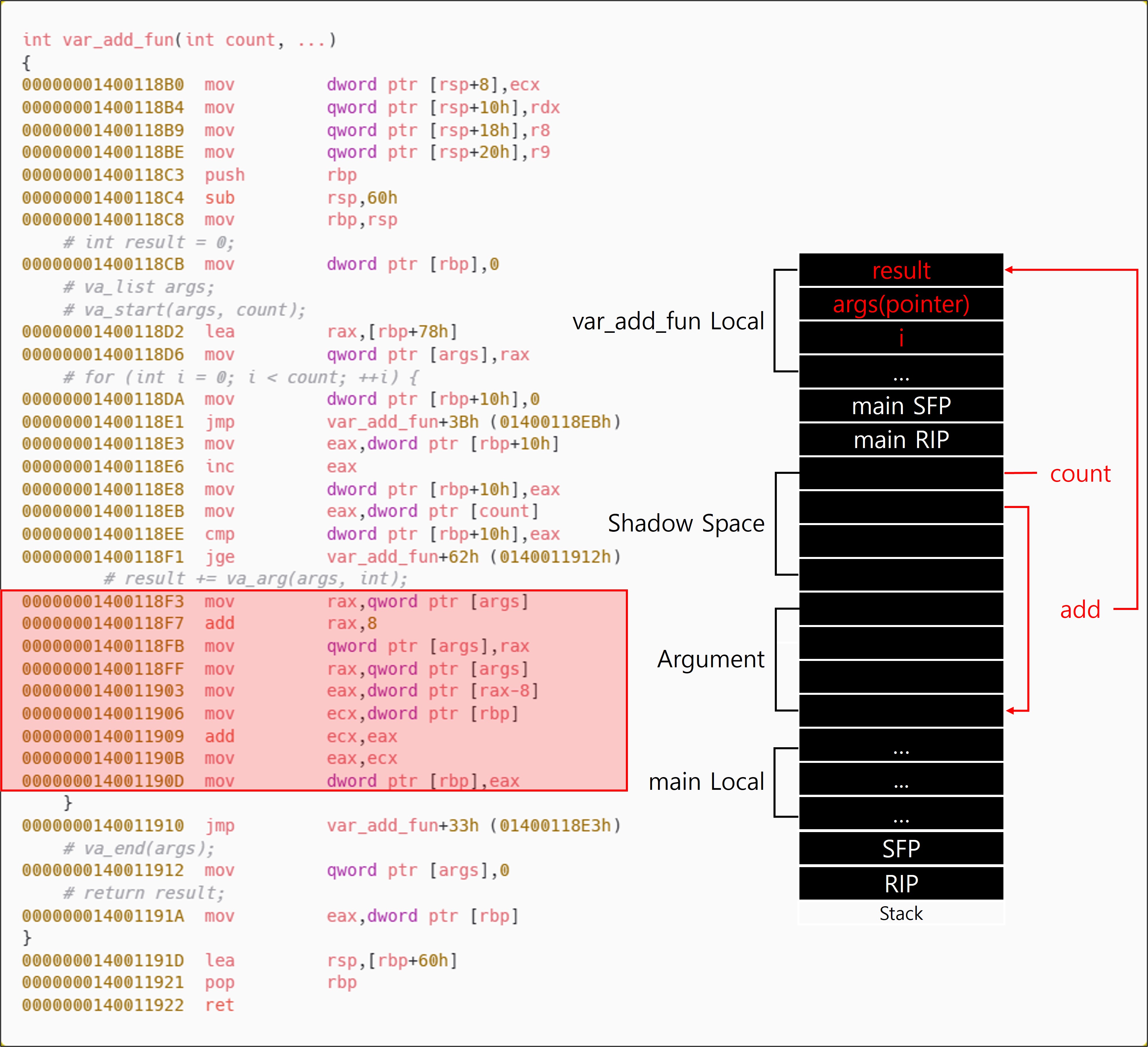
var_add_fun 함수가 동작하는 방식은 매우 단순하다. va_start를 통해 가변인자의 시작 주소(count 다음 인자)를 지정한다. 이후 count 만큼 인자를 result에 누산한다.

인자의 수가 가변적이라 하더라도 인자는 Caller(호출자)에 의해 호출 시점에 스택에 적재되므로 Callee(피호출자)의 로컬 영역 크기에는 영향을 미치지 않는다. 즉, var_add_fun(int count, ...)과 같은 가변 인자 함수에서 count 이후의 가변 인자들은 단순히 기존 스택 프레임 상의 인자 영역을 순회하는 방식으로 동작한다. 따라서 가변 인자의 존재 여부나 개수는 함수 내부에서 별도의 로컬 변수를 추가로 선언하거나, 스택 공간을 새로 확보해야 하는 요소가 아니므로 Callee(피호출자)의 로컬 영역 크기는 일정하게 유지된다. x32도 같은 방식으로 동작한다.
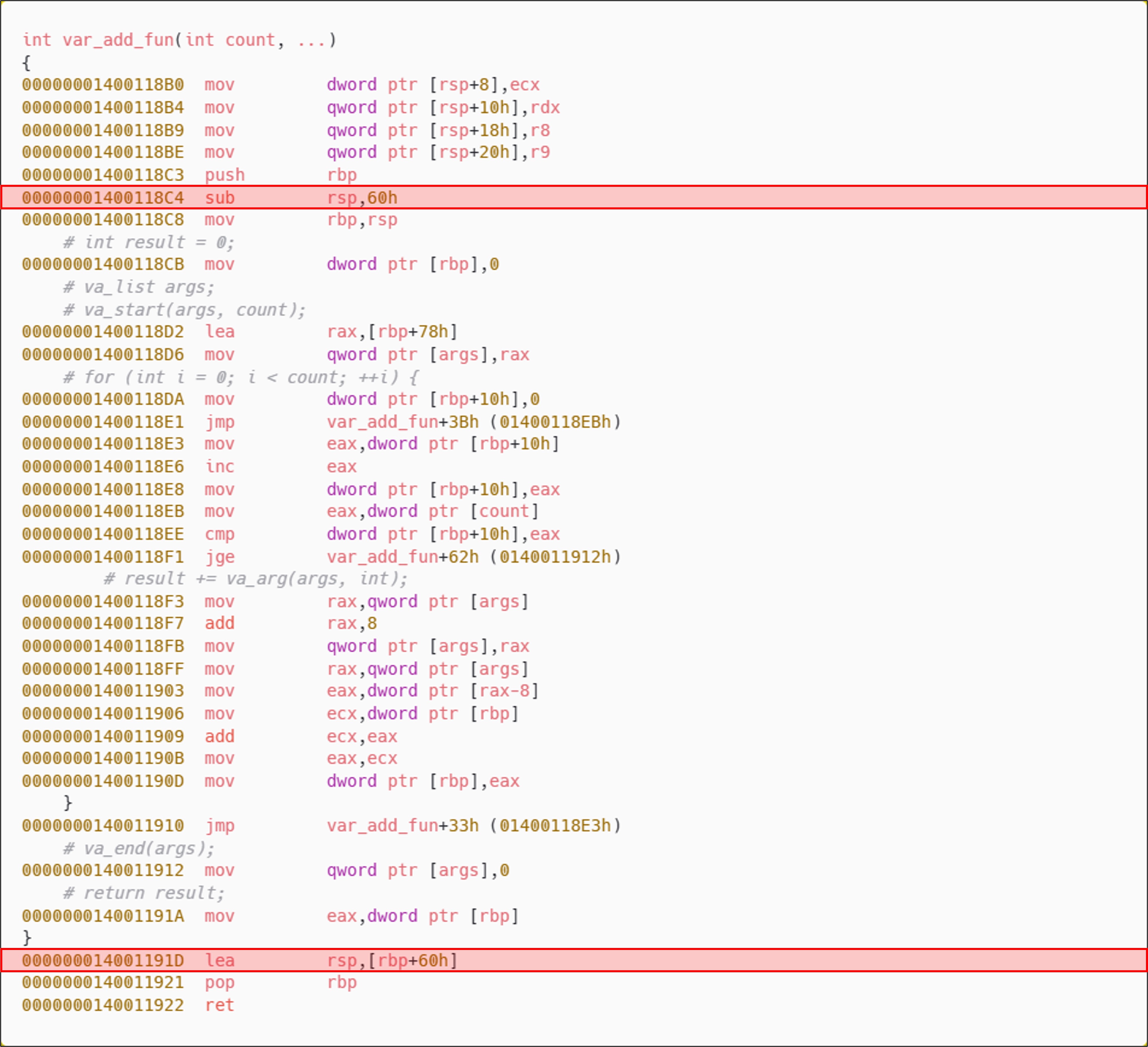
따라서 인자의 수가 가변적 이더라도 Callee(피호출자)는 자신이 확보한 로컬 영역을 명확히 알고 있기 때문에 에필로그에서 정확하게 정리할 수 있다. 하지만 x64에서도 마찬가지로 Callee(피호출자)는 가변 인자의 수를 알 수 없기 때문에, 인자 영역 전체의 정리는 Caller(호출자)가 책임진다.
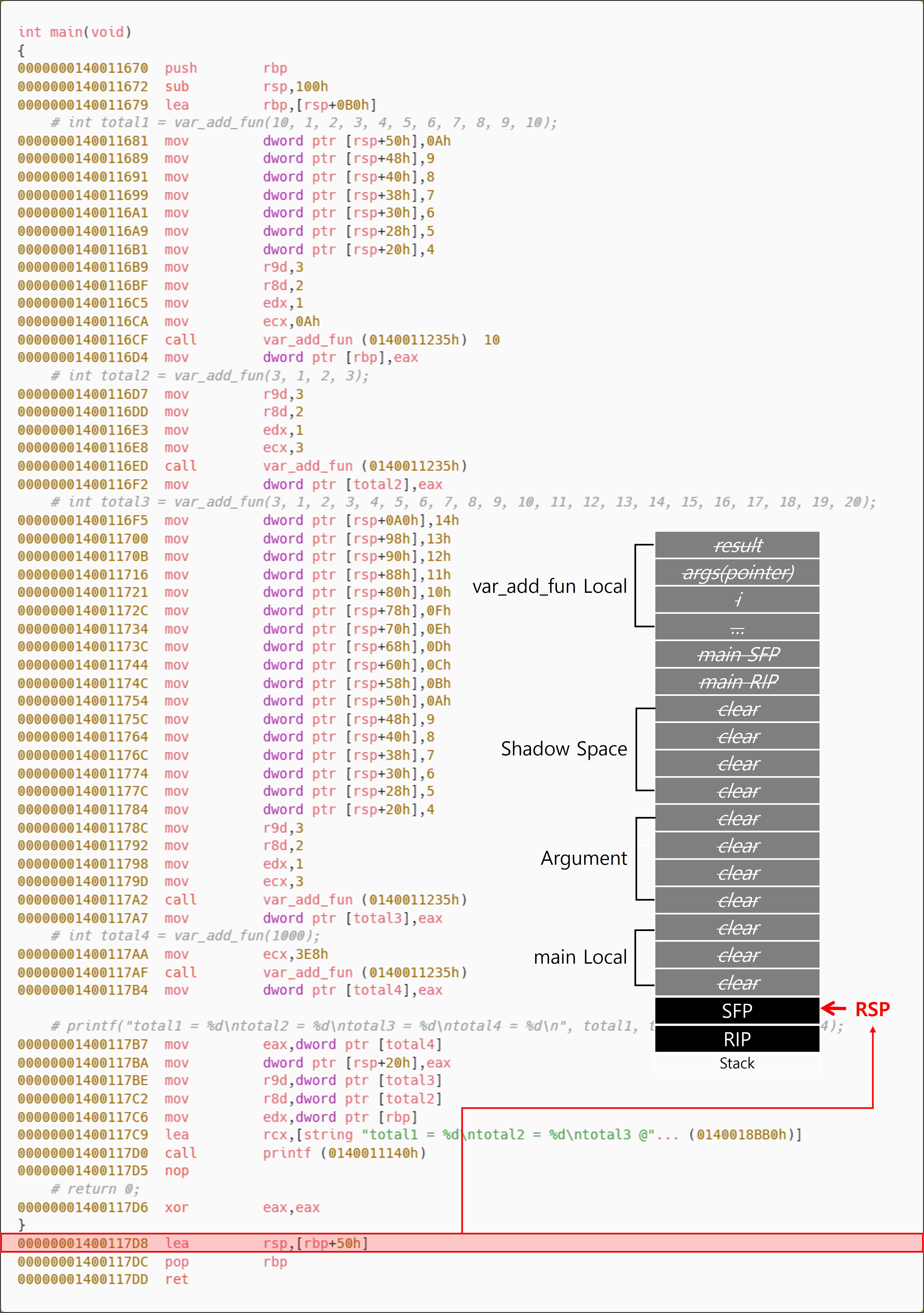
x64 함수 호출 규약에서는 인자 전달을 위한 스택 영역(Shadow Space 포함)을 Caller(호출자)가 함수 호출 직전에 한 번에 확보하고, 한 번에 정리한다. Caller(호출자)는 호출 당시 가변 인자의 개수와 전체 크기를 알고 있으므로 스택을 정리할 수 있다.
7. x32와 x64의 인자 영역 비교
7-1. Push Model (x32 Calling Convention)

x32에서 인자를 스택으로 전달할 때는 주로 push 명령어를 통해 인자를 하나씩 역순으로 적재하는 방식이 사용된다. 따라서 호출되는 함수마다 인자의 개수에 따라 스택에 쌓이는 Argument 영역의 크기가 달라진다는 특징을 갖는다. 이러한 구조에서는 각 호출 지점마다 Argument 영역의 형태가 일정하게 유지되지 않는다.

x32에서는 주로 push 명령을 사용해 인자를 스택에 적재하므로, 함수를 호출할 때마다 인자의 수만큼 스택에 쌓이게 되며, 이러한 호출이 반복될수록 인자 영역이 누적되어 전체 스택 사용량이 점점 증가한다. 같은 함수가 반복적으로 호출되는 경우, 컴파일 시점에는 최종적으로 얼마나 많은 인자들이 스택에 쌓일지 예측할 수 없기 때문에, 누적된 인자들로 인해 Stack Overflow 예외가 발생할 수 있다. 이러한 위험을 방지하기 위해, __cdecl에서는 함수 호출 직후 add esp, imm의 명령을 통해 곧바로 인자 영역을 정리하며, __stdcall, __fastcall, __vectorcall에서는 함수 동작이 완료된 직후, Callee(피호출자)에서 해당 인자 영역을 곧바로 정리한다. 이를 통해 인자 누적으로 인한 스택 오버플로우를 사전에 차단할 수 있도록 설계되어 있다.
7-2. Mov Model (x64 Calling Convention)

x64에서 인자를 스택으로 전달할 때는 주로 한번에 스택을 확보한 뒤, mov 명령어를 통해 인자를 적재하는 방식이 사용된다. 따라서 호출되는 함수의 인자의 개수에 상관없이 Argument 영역의 크기가 고정적이라는 특징을 갖는다. 이러한 구조에서는 각 호출 지점마다 Argument 영역의 형태가 일정하게 유지된다.

호출되는 함수들은 Argument 영역을 공유하는 방식으로 동작하며, mov 명령어를 통해 각 함수는 이전 호출에서 사용된 인자 위에 자신의 인자를 덮어쓰는 방식으로 이 영역을 재사용한다. 이때, 인자 값을 별도로 지우는 동작은 존재하지 않으며, 새로운 호출이 기존 값을 무시하고 자신의 값으로 덮기 때문에 정리가 불필요하다. 이와 같은 구조를 고려해 컴파일러는 모든 함수 호출에서 필요한 최대 인자 공간을 분석한 뒤, 함수 프롤로그에서 sub rsp, imm 명령을 통해 확보할 전체 스택 공간에 해당 Argument 영역까지 포함시킨다. 고정된 크기의 공유 영역을 반복적으로 덮어쓰며 사용하는 방식으로 효율성과 정렬 요건을 동시에 만족할 수 있게 된다.

x64에서는 주로 mov 명령을 사용해 인자를 스택에 적재하므로, 같은 함수를 여러 번 호출하더라도 Argument 영역의 크기는 고정적으로 유지된다. 이는 인자 전달을 위한 메모리 공간이 호출 시마다 새로 쌓이는 것이 아니라, 미리 확보된 일정한 영역에 값을 덮어쓰는 방식으로 구성되기 때문이다. 반면 x32의 push Model은 호출할 때마다 인자 수만큼 스택이 확장되기 때문에 호출이 반복될수록 인자들이 누적되는 구조이며, 이를 정리하지 않으면 Stack Overflow 예외가 발생할 수 있다. x64에서는 이러한 Argument 영역의 누적이 발생하지 않기 때문에, 함수 호출 이후 곧바로 인자를 정리하는 명령이 필요하지 않게 된다. 따라서 Caller(호출자)의 에필로그에서 한번에 전체 스택을 정리할 수 있는것이다. 다만, 함수의 호출이 깊어지는 경우에는 Stack Overflow 예외가 발생할 수 있다. 이러한 상황은 인자 영역의 누적이 아닌, 반복된 호출로 인한 전체 프레임의 중첩으로 인해 발생한다.
7-3. x32와 x64의 인자 전달 구조 차이의 설계 배경
32bit 환경은 4byte 정렬만 지키면 되었기 때문에, push 명령을 연속적으로 사용해 인자를 스택에 쌓아도 정렬 문제가 발생하지 않았다. push는 값 저장과 스택 포인터 조정을 1byte 명령으로 처리할 수 있어 코드 밀도와 실행 효율 면에서도 매우 유리했으며, 제한된 레지스터 수와 함께 레지스터를 아끼기 위한 현실적인 대안이었다. 반면 64bit 환경은 ABI 수준에서 스택 포인터(RSP)가 16바이트 정렬을 유지해야 하며, 함수 바디에서는 push 명령 사용이 사실상 금지된다. 이는 push가 8byte 단위로 RSP를 변경하기 때문에 사용 시 정렬을 깨뜨리기 때문이다. 이러한 제약 속에서 x64는 프롤로그에서 미리 스택 공간을 한 번에 확보한 뒤, 그 안에서 각 인자를 mov 명령으로 고정된 오프셋에 저장하는 모델로 전환되었다. 이 방식을 통해 스택 정렬을 유지할 수 있었으며, 고정된 주소 오프셋에 접근하므로 실행이나 메모리 접근 최적화에도 유리했다. 결국 x32와 x64의 인자 전달 방식 차이는 아키텍처별 정렬 요건과 ABI에서 요구하는 제약 조건 등 구조적인 설계 원칙에 따라 결정된 결과이다.
8. 참고 문헌
[1] x64 호출 규칙, https://learn.microsoft.com/ko-kr/cpp/build/x64-calling-convention?view=msvc-170
'Reversing > Definition' 카테고리의 다른 글
| [Definition] x64 ABI (2) | 2025.07.22 |
|---|---|
| [Definition] x32 ABI (0) | 2025.07.22 |
| [Definition] 64비트 스택 프레임 (64bit Stack Frame) (0) | 2025.07.15 |
| [Definition] 32비트 함수 호출 규약 (32bit Calling Convention) (5) | 2025.07.14 |
| [Definition] 32비트 스택 프레임 (32bit Stack Frame) (0) | 2025.07.13 |



